출처 : http://raonism.net/CSdb/protocol/rfc1945-kr.html

RFC 1945 - Hypertext Transfer Protocol -- HTTP/1.0
Network Working Group
Request for Comments: 1945
Category: Informational
T. Berners-Lee : MIT/LCS
R. Fielding : UC Irvine
H. Frystyk : MIT/LCS
May 1996
하이퍼텍스트 전송 프로토콜 - HTTP/1.0
305-350, 대전광역시 유성구 가정동 161번지
한국전자통신연구소 멀티미디어표준연구실
김 용 운
E-mail : qkim@pec.etri.re.kr
URL : http://pec.etri.re.kr/~qkim/
- Abstract:
- HTTP는 HyperText Transfer Protocol의 약자이며, 분산환경 및 공동작업 환경에 이용할 하이퍼미디어 정보시스템의 개발을 목적으로 설계된 응용계층의 프로토콜로서 WWW에서의 하이퍼텍스트 문서의 전송을 위해 쓰이는 프로토콜이란 뜻이다. 또한 요구 명령어의 추가를 통해 네임 서버나 분산 객체 관리 시스템 등과 같은 여러 가지 일에도 사용할 수 있는 객체 지향 프로토콜이며, 글에서 보이는 HyperText 문서만이 아니라 음성, 화상, 데이타 등과 같이 MIME에 의해 정의될 수 있는 모든 문서 형식을 전송할 수 있다. 이와 같은 HTTP 프로토콜의 구조와 동작 메카니즘에 대해 살펴보고자 한다.
- Keywords:
- HTTP, Protocol, BNF, Message, Header, Request, Response, Entity, Method, Proxy, Cache, Access Authentication
- Status:
- 이 문서는 ftp://ds.internic.net/rfc/rfc1945.txt 문서를 정리한 것이다. 본문 속에 들어있는 모든 내용이 그대로 또는 보완 설명되어 있다. 본 문서인 Korean Version 3.0이 위치하는 곳은 http://pec.etri.re.kr/~qkim/HTTP/http10v3.html 이며, 이전 문서인 Korean Version 2.0이 위치하는 곳은 http://pec.etri.re.kr/~qkim/HTTP/http10v2.html 이고, 이 이전 문서인 Korean Version 1.0이 위치하는 곳은 http://pec.etri.re.kr/~qkim/HTTP/http10v1.txt 이다. WWW에서 사용하는 각종 프로토콜에 대한 문서 정리는 http://pec.etri.re.kr/~qkim/HTTP/에 정리되고 있으며 문서 내용의 변경에 대한 알림글이 있다.
1. 서론
1.1 HTTP vs. TCP/IP
HTTP는 World Wide Web에서 사용하고 있는 데이타 송수신 프로토콜이며 TCP 수송계층 프로토콜을 기반으로 하는 응용계층의 프로토콜이다. 그러므로 TCP 전송의 특성에 따라서 모든 데이타 형식에 대해 8-bit 이진모드로 전송할 수 있다.
여기서 8-bit 이진모드 전송이라 함은 1-bit도 빠짐없이 완전무결하게 전송된다는 것이며, 7-bit 아스키모드 전송이라 함은 8-bit 기본 단위에서 MSB 1-bit의 완전무결성을 보장하지 못 한채 전송된다는 것이므로 데이타 전송에 오류가 생길 가능성이 있다. 따라서 아스키 텍스트 문서를 전송할 때는 7-bit 아스키모드로 전송을 해도 되지만 실행파일과 같은 이진 데이타를 전송하고자 할 때는 반드시 8-bit 이진모드로 전송하여야만 한다.
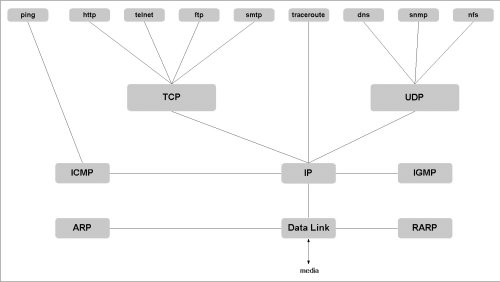
[그림 1] TCP/IP Protocol Stack[19]
그러므로 HTTP 전송 프로토콜이 이진모드로 데이타를 전송한다는 것은 TCP/IP 프로토콜 체계 가운데 TELNET이나 FTP와 같이 TCP 전송 프로토콜 상에서 활용되는 응용 프로토콜의 한 가지임을 뜻하며, 다만 WWW 용의 규약 정보가 HTTP 프로토콜로서 활용되고 있을 뿐이다. 즉, 그림 1과 같이 나타낼 수 있다.
TCP/IP 프로토콜에서는 TCP 전송 프로토콜을 이용하는 응용 프로토콜들 사이의 구별을 port 번호를 통해 해결하고 있다. 그러므로 HTTP 응용 프로토콜에 할당되어 사용하는 TCP 포트가 있으며 80번으로 지정되어 있다. 정의되어 있지 않은 다른 임의의 포트를 이용할 수도 있으나 기본적으로 정의되어 있는 번호는 80번이다.
그렇다고 해서 HTTP 프로토콜은 TCP/IP에서만 동작할 수 있는 것은 아니다. OSI 참조모델을 이용한 프로토콜 체계에서도 수송계층의 전송 프로토콜 상에서 HTTP 프로토콜은 응용 프로토콜로서 활용될 수 있는 것이다. 다만 다른 프로토콜 체계에서 사용하고자 할 때는 그에 맞게끔 약간의 적절한 수정을 해야만 가능할 것이다.
버전 1.0 HTTP 프로토콜(HTTP/1.0)은 IETF (Internet Engineering Task Forces)에 의해 RFC 1945로 정식 등록되었으며, 버전 1.1은(HTTP/1.1)은 Proposed Standard로 등록되어 RFC editor에 의해 재작성된 후 RFC로서 새로이 등록될 예정이다. 현재의 WWW에서 쓰이고 있는 HTTP 프로토콜은 1.0 버전이며 1.1 버전의 것이 구현되고 있는 중이고 '96년 10월 현재 W3C에서 발표한 Amaya와 Jigsaw가 1.1 버전을 구현한 것이다.
1.2 HTTP의 등장 배경 및 목적
실제적인 정보시스템에서는 검색, 정보 갱신, 및 주석 등과 같은 간단한 작업보다는 더욱 다양한 기능을 필요로 하고 있다. 또한 분산 환경, 공동작업 환경, 하이퍼미디어 정보시스템 등의 상황에서 필요로 하는 빠른 속도와 간편성을 제공하기 위한 응용계층의 프로토콜이 필요하게 되었고 이를 목적으로 HTTP 프로토콜이 설계되었다.
이에 따라 대상체의 위치나 이름을 지정하는 URI로부터 제공되는 정보를 이용하여, 대상 화일을 어떻게 활용할 것인가 지정하는 method의 집합에 따라서 적절한 기능 동작을 하게끔 HTTP는 설계되어 있다. 이에 따라 송수신되는 프로토콜 구성체는 메시지라는 이름으로 불리우며 Internet Mail과 MIME에서 사용하는 방식과 비슷하게 구성되어 송수신된다.
또한 HTTP는 사용자 브라우저와 프락시 서버 또는 게이트웨이 사이에서 SMTP, NNTP, FTP, Gopher, WAIS 등과 같은 기존 프로토콜과의 통신을 가능하게 해주는 프로토콜의 역할을 하게끔 할 수도 있다. 이에 따라 기존의 축적되어 있는 하이퍼미디어 정보들을 그대로 활용할 수 있게 하며 사용자 브라우저의 구현도 단순화 시킬 수 있게 한다.
이 문서는 "HTTP/1.0"으로서 알려진 HTTP 프로토콜의 활용에 관한 것이며 대부분의 HTTP/1.0 클라이언트와 서버에 구현되어 있는 기능 및 특징들에 관한 사항을 다루고 있다.
이 문서는 두 가지 부분으로 구성되어 있으며 대부분의 에이전트에서 구현되어 있어 다른 에이전트들과도 일관적으로 잘 동작하는 기능 특성들을 앞부분에 포함하고 있고, 특정 에이전트에만 구현되어 있어 다른 에이전트들과 일관적으로 쓰이지 않는 기능 특성들은 부록 D에 포함하고 있다.
1.3 HTTP 프로토콜 규격서에 쓰이는 용어
HTTP 프로토콜 설명서에는 여러 가지 용어들이 쓰이고 있으며 주요 용어들에 대해 설명하도록 한다.
- 연결(connection)
- 데이타 송수신을 위해 두 개의 응용 프로그램 사이에 TCP 데이타 전송 프로토콜을 이용해서 만들어진 가상적인 연결선이다.
- 메시지(message)
- HTTP 프로토콜의 통신을 위해 사용되는 기본적인 송수신 단위이다. 연결을 통해 전송되며 제4장에 정의되어 있는 표현식과 일치되는 구조적 데이타열이다.
- 요구(request)
- HTTP 프로토콜 상에서 브라우저가 어떤 데이타 요구를 하기 위해 보내는 HTTP 메시지. (제5장 참조)
- 응답(response)
- HTTP 프로토콜 상에서 수신한 요구에 대해 서버가 처리한 결과를 브라우저에게 응답으로 보내는 HTTP 메시지. (제6장 참조)
- 자원(resource)
- URI에 의해 지정될 수 있는 서비스 또는 통신망 상의 데이타
- 엔터티(entity), 개체
- 데이타 자원의 특정한 표현 형태나 연출된 형태, 또는 어느 서비스 자원으로부터의 응답이 엔터티가 될 수 있으며, 이것은 요구 또는 응답 메시지에 포함될 수 있어야 한다. 엔터티는 엔터티 영역에 있는 내용과 엔터티 헤더의 형태로 되어 있는 메타정보(metainformation, 4.6절 참조)로 구성되어 있다.
- 클라이언트(client)
- HTTP 프로토콜 규약에 맞추어 요구를 보내고 서버가 보내오는 응답을 수신하는 역할을 하며, 이런 송수신에 있어 요구 메시지를 전달하기 위한 연결을 설립하는 응용 프로그램.
- 사용자 에이전트(user agent)
- 요구를 발생시키는 역할을 하는 클라이언트 프로그램을 말한다. 브라우저, 문서작성기, 스파이더(웹검색 로보트), 또는 다른 사용자 도구들이 그 예이다.
- 서버(server)
- 요청받은 서비스를 제공해주기 위해 연결을 허용하는 응용 프로그램.
- 원서버(origin server)
- 프락시 서버와 같이 중계해주는 것이 아니라 최종적으로 실제 데이타를 저장해두고서 수신한 요구에 대해 서비스를 제공하거나, 요구에 의해 저장할 수 있는 장소를 제공하는 서버이다.
- 프락시(proxy)
- 다른 클라이언트 프로그램과의 사이에서 서버로서도 클라이언트로서도 동작하는 중계 프로그램이다. 요구는 내부적인 동작에 의해 처리되든지, 아니면 가능한 변환을 통해 다른 서버로 전달되든지 한다. 프락시는 중계해주기에 앞서 요구 메시지를 해석해 보아야 하고, 필요하다면 적절히 다시 만들 수 있어야 한다. 프락시는 방화벽을 통과하는 클라이언트측 통로로서, 또는 사용자 에이전트에 구현되어 있지 않은 프로토콜에 따른 요구를 처리할 수 있는 도우미 응용 프로그램으로서 종종 쓰인다.
- 게이트웨이(gateway)
- 다른 어떤 서버와의 중계 역할을 하는 서버이다. 프락시와는 달리 브라우저가 요구한 자원에 대해 마치 자신이 원서버인 것처럼 동작하여 중계 서비스 해준다. 따라서 게이트웨이는 브라우저에 대해 원서버처럼 동작함으로써 브라우저는 제공받은 서비스가 게이트웨이로부터 전달된 것인지 모른다. 게이트웨이는 방화벽을 통과하는 서버측 통로로서, 또는 HTTP 시스템이 아닌 곳에 저장되어 있는 자원에 대해 접근하는 프로토콜 변환기로서 종종 활용된다.
- 터널(tunnel)
- 터널은 두 개의 연결 사이에 무조건 중계 (blind relay)의 역할을 하는 중계 프로그램이다. 일단 동작하기만 하면 터널은 어느 HTTP 요구에 의해 생성되었음에도 불구하고 HTTP 통신에 있어 한 끝단(한 연결선의 송신측 또는 수신측)으로 간주할 수는 없다. 중계되는 연결선의 양쪽 끝단이 해제될 때 터널도 해제된다. 터널은 어떤 통과문이 필요하지만 중계 프로그램이 중계되는 통신 데이타에 대해 해석할 수 없거나 해석해서도 안 되는 경우에 사용할 수 있다.
- 캐시(cache)
- 응답받은 메시지를 자신의 컴퓨터에 저장한 장소 또는 저장/검색/삭제가 가능하도록 만든 저장 시스템이다. 저장 가능한 데이타를 저장해두고 있다가 같은 데이타인 경우 다시 가져오지 않고 저장되어 있는 것을 보여주도록 하여 응답 시간을 빠르게 하고 통신망 이용의 효율성을 높인다. 어떤 클라이언트나 서버이든 캐시가 터널로서 동작하고 있는 동안에는 서버에 의해 사용될 수 없음에도 불구하고 캐시를 포함할 수도 있다.
어떤 프로그램은 클라이언트나 서버로서 둘 다 동작할 수 있으나, 이 경우에는 특정한 연결에 대해 이 프로그램이 하는 역할에 따라 규정될 수 있다. 마찬가지로 어떤 서버는 각각의 요구에 따라서 원서버, 프락시, 게이트웨이, 또는 터널로서 동작할 수도 있다.
1.4 HTTP 프로토콜의 동작
HTTP 프로토콜은 요구/응답 (Request/Response) 방식을 이용하여 동작하고 있다. 즉, 원하는 프로토콜 기능(예: GET, HEAD, POST)에 대해 서비스 요구를 하면 데이타 송수신을 위한 TCP 연결이 만들어지고, 서버가 응답을 보내어 데이타 전송을 끝내면 자동적으로 연결이 끊어지게 되는 것이다.
클라이언트가 서버와 TCP 연결을 만들고, 요구 method, URI, 프로토콜 버전, MIME의 형태로 표시되는 클라이언트 지정 사항들, 클라이언트 정보, 때로는 서버에게 전달할 내용 데이타까지 포함하는 요구 메시지의 형태로 서버에게 보낸다. 이에 대해 서버는 상태 정보를 보내는데, 프로토콜 버전, 성공 또는 오류코드 번호, 그리고 MIME의 형태로 표시되는 서버 정보를 포함하고, 엔터티의 메타정보, 전달할 내용 데이타 등을 포함하는 응답 메시지를 클라이언트에게 보낸다.
대부분의 HTTP 통신은 사용자 에이전트가 생성시키고 어떤 원서버에 있는 대상 자원에 적용할 요구 메시지를 전달하는 것이다. 가장 간단한 경우로서 사용자 에이전트(UA)와 원서버(O) 사이에 설립된 연결(v)에 대한 것을 볼 수 있다.
이에 대한 간단한 예를 아래에서 살펴보도록 한다.
- Request
- HTTP의 Request 형식은 아주 간단하다. 첫 번째 줄 처음에 서버의 어떤 기능을 이용하려는지 지정을 하며 이것이 method이다. 가장 일반적으로 쓰이고 있는 것은 GET 이다. 이것은 브라우저가 서버에게 문서를 보내달라고 요청하는 것이다. 그 다음에는 화일 이름과 위치하는 디렉토리 이름 등이 들어가는 URI를 지정하고 현재 쓰이고 있는 HTTP 프로토콜의 버전을 지정한다. 이 다음에는 MIME 형식으로 표현되는 일련의 지정 사항들을 덧붙일 수가 있는데, 예를 들어 브라우저의 종류 같은 것이다. 아래와 같은 예를 볼 수 있으며, Request chain이란 아래와 같이 여러 헤더로 구성되어 있는 요구 메시지를 일컫는 말이다.
Request Example
GET /index.html HTTP/1.0 From: qkim@pec.etri.re.kr Referer: http://pec.etri.re.kr/~qkim/qkim.html User-Agent: Netscape 1.2 - Response
- HTTP에서의 응답 형식도 아주 간단하게 구성되어 있다. 서버에서 쓰이고 있는 프로토콜 버전, Request에 대한 실행 결과 코드 및 설명문이 있으며, 전달해줄 데이타의 형식, 데이타 길이 등과 같은 추가적인 정보가 MIME 형식으로 표현되어 있다. 이어서 마지막에 헤더 정보의 끝을 나타내는 빈줄이 들어가고, 뒤이어 실제 데이타가 전달된다. 데이타 전달이 끝나면 서버는 연결을 끊는다. Response chain이란 여러 가지 헤더로 구성되어 있는 응답 메시지를 일컫는 말이며, 아래와 같은 예를 볼 수 있다.
Response Example
HTTP/1.0 200 OK Server: MDMA/0.1 Content-type: text/html Last-Modified: Thu Jul 7 00:25:33 1994 Content-Length: 2003 Right here waiting for you...
이상과 같은 간단한 예가 아니라 보다 복잡한 상황을 가정할 수 있는데, 이것은 하나 또는 그 이상의 중계 프로그램이 요구/응답 메시지들의 교환 사이에 있을 때이다. 중계 프로그램은 세 가지 형태의 것이 존재하는데, 프락시, 게이트웨이, 그리고 터널이다.
프락시는 포워딩 에이전트로서 요구 메시지를 수신하여 절대경로의 URI로 메시지를 전부 또는 부분 재작성하여 URI에 지정한 서버로 전달하는 역할을 한다. 게이트웨이는 수신 에이전트로서 서버 상위의 어떤 계층으로서 동작하며, 필요하다면 하위 계층 서버의 프로토콜로 요구 메시지를 변환하는 역할도 한다. 터널은 메시지 변환 없이 두 개 연결 사이의 중계점 역할을 하며, 메시지의 내용은 이해할 수 없다 할지라도 통신 경로가 방화벽과 같은 중간 지점을 통과할 필요가 있을 때 사용된다.
이와 같은 상황에 대한 예를 보이면 아래와 같다. 여기에는 사용자 에이전트와 원서버 사이에 세 개의 중간 프로그램이 (A, B, 및 C) 존재하고 있다. 모든 사슬을 통과하는 요구 또는 응답 메시지는 반드시 네 개의 개별 연결선을 경유하여야 한다. 이러한 각각의 구분은 중요한데, HTTP 통신에 있어서 어떤 지정 사항들은 가장 가까운 연결선에만 해당하는 것일 수 있고, 또는 양 끝단에 해당하고, 전체 연결선에도 모두 해당하는 것일 수 있기 때문이다.
위 그림은 하나의 선형적 연결선으로 보이지만 실제로 각각은 동시에 존재하는 여러 개의 연결선에 참여하고 있다.
터널로서 동작하지 않는 경우에 있어, 사용자 에이전트가 보낸 요구 메시지의 응답이 중간 경로에 이미 캐시되어 있는 것으로서 여전히 유효한 응답이라면 원서버까지 요구 메시지가 전달되지 않고도 해당 응답이 전달될 수 있다. 이에 대한 그림이 다음의 것이다.
위 그림의 경우, UA가 보낸 요구 메시지에 대한 응답이 O로부터 C를 거쳐 이미 B에 캐시되어 있으므로 B로부터 UA로 곧바로 응답이 전달되는 것을 보인 그림이다. 모든 응답이 캐시될 수 있는 것은 아니며 또한 어떤 요구는 캐시 동작에 대한 특정 요구사항이 첨부되는 지정 사항을 포함할 수도 있다.
인터넷 상에 있어 HTTP 통신은 TCP/IP 연결 상에서 동작하고, 기본 설정되는 포트 번호는 TCP 80번이며 다른 포트 번호도 사용할 수 있다. 그러나 이 사실이 HTTP 프로토콜은 인터넷의 다른 프로토콜 또는 다른 네트워크 상에 구현되어서는 안 된다는 것을 뜻하는 것은 아니며, HTTP가 가정하는 것은 신뢰성 있는 전송이 보장되어야 한다는 것이므로 이것이 가능한 어떤 프로토콜 상에서도 동작이 가능하다. 이때 다른 종류의 프로토콜 상에 올리기 위한 HTTP/1.0 요구/응답 메시지 구조의 변환은 이 문서가 다룰 내용이 아니다.
실험적인 응용 프로그램을 제외한 실제 응용에 있어서 각 요구 메시지 전달에 앞서 클라이언트에 의해 연결이 먼저 설립되어야 하고 서버가 응답을 먼저 보내고 연결을 끊도록 하여야 한다. 이때 클라이언트와 서버는 사용자의 동작이나 자동적인 타임아웃, 또는 프로그램 오류에 의해 어느 쪽이든 도중에 연결을 해제할 가능성도 있다는 것을 알아야 하며, 적절한 대응 동작을 할 수 있어야 한다. 어떤 경우에든 어느 한 쪽 또는 양쪽 모두의 연결 해제는 항상 현재 요구에 대한 삭제를 뜻한다.
1.5 HTTP와 MIME
HTTP/1.0은 RFC 1521에 정의되어 있는 MIME의 구성 요소들 가운데 많은 부분들을 활용하고 있다. 부록 C에 두 가지 요소에 대한 관련을 기술하고 있다.
1.6 HTTP 프로토콜의 구성
HTTP 프로토콜이 구성되어 있는 형식을 표현하기 위한 방법이 있는데 여기서 사용하는 것은 BNF (Backus-Naur Form) 형식이며 여기에 약간의 보충을 하여 이용하도록 한다. 이를 위해 표현 형식에 대한 설명을 먼저 하도록 하고, 프로토콜 형식의 표기상 사용한 약속을 정의하고, 이어서 HTTP 프로토콜로서 동작하는 메시지의 종류와 구조를 살펴보도록 한다. TCP/IP 연결을 통해 송수신되는 HTTP 프로토콜 데이타는 메시지라는 종류로 구분되고 있다. 즉, 요구 메시지와 이에 대한 응답 메시지가 바로 그것이다. 이 속에 구성되어 있는 규격이 HTTP 프로토콜 규격이 된다.
2. BNF (Backus-Naur Form) 형식
2.1 확장 BNF이 문서에 포함되어 있는 모든 메카니즘들은 RFC 822에서 사용하고 있는 것과 비슷하게 BNF와 이에 대한 정의 설명으로 표현되어 있다. 구현자들은 이것을 숙지하여 HTTP 프로토콜 규격서를 이해하면서 구현하여야 한다. 확장 BNF는 다음과 같다.
- name=definition
- 어떤 규칙의 이름 그 자체를 나타내고 ("<"와 ">" 속에 표시하지는 않는다) 이에 대한 정의는 "=" 표시로 구분한다. 빈 공백은(whitespace)는 한 줄 이상의 여러 줄로서 표시되는 규약에 있어 다음 줄로 계속 이어짐을 나타내는 들여쓰기(indentation)의 의미로서만 쓰인다.
Request = Simple-Request | Full-Request 또는,Method = "GET" | "HEAD" | "POST" | extension-method SP, LWS, HT, CRLF, DIGIT, ALPHA 등과 같이 대문자로 표시되는 기본 규칙도 있으며, 꺽쇠 표시는 ("<"와 ">") 규칙 이름을 식별하고자 할 때 정의문 내에서 사용된다. 다음과 같은 예를 볼 수 있다.DIGIT = <any US-ASCII digit "0"..."9"> - "literal"
- " " 표시 사이에 들어가는 것은 단어 그 자체로서 표현되는 것이다. 따라서 HTTP 프로토콜에서는 이 문자 그대로 송수신된다. 다음과 같은 예를 살펴볼 수 있는데, 뒤에서 나올 프로토콜 규격에 나오는 weekday란 부분은 일곱 가지 요일 가운데 하나가 글자 그대로 전달된다는 것이다. 이와 같은 표시가 없는 경우에는 대소문자를 가리지 않는다.
weekday = "Monday" | "Tuesday" | "Wednesday" | "Thursday" | "Friday" | "Saturday" | "Sunday" - rule1 | rule2
- OR 조건을 나타낸다. 따라서 두 가지 가운데 한 가지를 택할 수 있다는 뜻이다.
- (rule1 rule2)
- 두 가지 요소로 구성되어 있으나 하나의 요소로서 취급한다는 뜻이다. 아래와 같은 예의 경우에,
"(elem (foo | bar) elem)" 이것은 "elem foo elem" 과 "elem bar elem" 두 가지로 구성된다는 뜻이다. - *rule
- 이것은 반복을 의미하는 것으로서 뒤이어서 나올 #rule과 혼동을 일으키는 표현 방식이므로 유의해야 한다. 반복을 통해 이루어지는 결과는 하나의 단어나 수와 같이 한 개 요소의 표현 형태로 되는 것이며, #rule에서는 똑같은 반복이지만 여러 개 단어나 수의 열 형태와 같이 여러 개 요소의 나열 형태로 표현되는 것이다. *rule의 표기 방법은 아래와 같이 해서 쓰인다.
<n>*<m>element 이것은 적어도 n개와 최대 m개의 요소로 구성되는 한 가지 결과를 의미한다. 즉, 1*2DIGIT 라는 표현은 숫자가 적어도 한 개 최대 두 개로 구성되어 한 개의 수를 나타낸다는 뜻이다. 4는 한 가지 예이며, 45도 한 가지 예가 된다. 그러나 345의 경우에는 숫자 세 개로 구성된 한 개 요소이므로 최대 갯수에 위배되어 적합하지 않다.n과 m은 생략될 수 있으며, 이 경우에 n의 기본값은 0이고 m의 기본값은 무한대이다. 그러므로 "*(element)"는 0개를 포함해서 어떤 갯수라도 가능한 표현법이다. "1*element"의 경우는 한 요소의 표현에 있어 적어도 한 개는 있어야 하며 최대 갯수에는 제한이 없다.
- [rule]
- 선택적으로 사용할 수 있다는 뜻이다. 예를 들어, "[foo bar]" 이것은 "foo bar"를 사용할 수도 있고 사용하지 않을 수도 있다는 것이다. 그러므로 "*1(foo bar)"로 표현할 수 있다.
- N rule
- 특정 횟수만큼의 반복을 나타낸다. 2DIGIT은 두 자리 숫자를 나타낸다는 것이다. 따라서 "
* 로 나타낼 수 있다.(element)" - #rule
- 앞서 설명한 것처럼 반복을 나타내긴 하지만 요소들의 나열로서 표현되는 것이다. 즉, 1#DIGIT 라고 하면 여러 개의 수로 구성된 수열로서 표현되는데, 최소 한 개의 수는 있어야 하고 최대 갯수는 제한이 없는 수열이 된다. 각 요소들 사이의 구분은 ","와 LWS를 이용하는데, 여러 개의 나열 형태를 쉽게 표현할 수 있게 해준다. 예를 들어,
(*LWS element *(*LWS "," *LWS element)) 이것을 간단하게 다음과 같이 표현할 수 있다.1#element 또 다른 예를 들자면,1#2(2DIGIT) 이것은 숫자 두 개로 구성된 수가 적어도 한 개가 있어야 하며 최대 두 개까지 가능하다는 것이다. 즉, 23 이렇게 표현될 수도 있고, 23, 56 이렇게 두 개로 표현될 수도 있다.이것이 *rule과의 차이점이고, #rule 에서도 "
# 의 구성이 그대로 성립한다. 이에 대한 설명은 *rule 의 경우와 같다. ","를 이용하여 나열함에 있어, null element가 허용된다. 예를 들어, 1#3(2DIGIT)과 같은 표현식에 대해element" 23, , 56, 34 이렇게 null element 표시가 가능하지만, 실제 갯수는 세 개로서 간주된다. 따라서 최소 한 개 최대 세 개의 제한에 위배되지 않는다. - ; comment
- 이것은 규칙에 대한 설명을 하기 위해 표시하는 부분이다. 줄의 끝까지가 이 표시가 미치는 영향이다. 따라서 다음 줄까지 설명문을 연장하려면 다음 줄 처음에 ; 표시를 하여야 한다. 즉, 다음과 같다.
Sun, 06 Nov 1994 08:49:37 GMT ; RFC 822 ; updated by RFC 1123 - implied *LWS
- 두 개의 인접한 단어 (token or quoted-string) 또는 인접한 토큰(tokens)과 식별자 (tspecials) 사이에 LWS (linear whitespace)가 포함될 수 있다. 여기서 두 개의 토큰 사이에는 반드시 적어도 하나의 식별자가 존재하여 각기 하나의 토큰으로 간주되지 않게끔 구별되어야 한다.
2.2 기본적인 규칙
다음의 규칙은 이 문서 전체에서 쓰이고 있으며, US-ASCII 글자는 Standard ANSI X3.4인 ANSI 표준 문서에 'Coded Character Set - 7-Bit American Standard Code for Information Interchange'란 이름으로 정의되어 있다.
OCTET = <any 8-bit sequence of data> CHAR = <any US-ASCII character (octets 0 - 127)> UPALPHA = <any US-ASCII oppercase letter "A" .. "Z"> LOALPHA = <any US-ASCII lowercase letter "a" .. "z"> ALPHA = UPALPHA | LOALPHA DIGIT = <any US-ASCII digit "0" .. "9"> CTL = <any US-ASCII control character (octets 0-31) and DEL(127)> CR = <US-ASCII CR, carriage return (13)> LF = <US-ASCII LF, linefeed (10)> SP = <US-ASCII SP, space (32)> HT = <US-ASCII HT, horizontal-tab (9)> <"> = <US-ASCII double-quote mark (34)> CRLF = CR LF - CR LF로 구성되어 있으며 Entity-Body를 제외한 모든 프로토콜 요소들에 대한 줄의 끝(end-of-line)을 표시한다. Entity-Body 내에 있는 줄의 끝 표시는 3.6절에 설명되어 있는 것처럼 관련 미디어 종류에 의해 정의된다.
LWS = [CRLF] 1*(SP | HT) - HTTP 프로토콜 헤더가 여러 줄로 구성될 수 있는데, 이때 다음 줄로의 계속 표시를 나타내는 데에 쓰인다. 줄의 첫 시작에 SP나 HT가 있으면 앞 줄의 계속으로서 인식된다.
TEXT = <any OCTET except CTLs, but including LWS> - LWS는 포함하나 모든 CTL 요소를 제외한 OCTET이다. 내용 설명 및 값 표시로서 쓰일 수 있으며 메시지 해석기(parser)에서 번역되지는 않는다. US-ASCII 문자집합 이외의 octets를 포함하는 TEXT 필드의 경우에는 ISO-8859-1 문자로 표현된 것이라고 간주한다.
HEX = "A" | "B" | "C" | "D" | "E" | "F" | "a" | "b" | "c" | "d" | "e" | "f" | DIGIT word = token | quoted-string - HTTP 프로토콜의 헤더 필드는 LWS 또는 특수 문자들에 의해 구분되는 단어들로 구성되어 있다. 이러한 특수 문자들은 파라미터 값 속에 <"> (quoted string) 표시에 의해 나타내진다.
token = 1*<any CHAR except CTLs or tspecials> - CTL 문자나 tspecials 문자를 제외한 하나 이상의 문자로 구성된 글자.
tspecials = "(" | ")" | "<" | ">" | "@" | "," | ";" | ":" | "\" | <"> | "/" | "[" | "]" | "?" | "=" | "{" | "}" | SP | HT - 위에서 <"> 표기는 "(" 의 경우와 똑같이 그 문자 자체를 나타낸다.
comment = "(" *(ctext | comment) ")" - HTTP 프로토콜 헤더 속에 괄호 표시로서 설명문을 포함시킬 수 있다.
ctext = <any TEXT excluding "(" and ")"> - 괄호를 제외한 어떤 문자라도 가능하다.
quoted-string = (<"> *(qdtext) <">) - 괄호 표시 속에 전체가 들어 있으므로 한 가지 요소로서 취급된다. 예를 들어, "I Love You!" 가 이의 예가 된다.
qdtext = <any CHAR except <"> and CTLs, but including LWS>
여기서 "\"를 사용하는 single-character quoting은 HTTP/1.0에서는 허용되지 않는다.
3. HTTP 프로토콜 파라미터
HTTP 프로토콜 규격 설명서는 메시지 단위의 설명으로 이루어져 있으며 이를 위하여 여러 가지 파라미터가 표현되어 있다. 이들 파라미터는 요구/응답 메시지의 헤더 필드에 대한 표현식에 사용되는 것이며, 각종 헤더 필드는 별도의 장에서 설명하도록 한다. 이러한 기본적인 파라미터들의 종류와 내용을 여기서 살펴보도록 한다.
3.1 HTTP Version
HTTP 프로토콜의 버전을 표현하기 위해 "<major>.<minor>" 방식을 사용한다. 여기서 major 부분은 프로토콜 메시지 형식의 변경과 같이 중요한 변경 사항이 있을 때 사용하는 것이고, minor 부분은 파라미터 변경과 같이 부수적인 사항들의 변경이 있을 때 사용하는 것이다. 현재 이루어지고 있는 프로토콜의 버전은 1.0이다. 각 숫자는 양의 정수를 사용하여 1씩 증가하도록 되어 있으므로, HTTP/2.13은 HTTP/2.4보다 상위 버전이다.
프로토콜의 버전을 나타내는 것은, 송신측이 요구(request)를 보낼 때 사용하는 메시지의 표현 형식을 나타내고 서버나 브라우저가 어떤 형식의 메시지를 이해하고 처리할 수 있는지 표시하는 중요한 요소이다.
minor 번호가 바뀔 때는 메시지 해석 알고리즘을 변경하지 않고도 프로토콜 기능에 대한 변화를 줄 수 있을 때이고, 프로토콜 내의 메시지 형식이 바뀔 때와 같은 큰 변화가 뒤따를 때 major 번호를 바꾼다.
HTTP 메시지의 버전은 HTTP-Version 필드를 통해 표시하며 메시지의 첫 번째 줄에 자리한다. 만약 프로토콜 버전이 표시되지 않으면 메시지 수신측에서는 HTTP/0.9 버전의 단순 형식으로 간주한다.
서버나 브라우저를 구현하고자 할 때 반드시 포함되어야 하는 HTTP 프로토콜은 0.9와 1.0 버전 모두이며, 이 문서 속에서는 둘 다 기술되어 있다.
이 문서에 정의되어 있는 Full-Request 또는 Full-Response 형식의 메시지를 전송하는 응용 프로그램에서는 "HTTP/1.0"이란 HTTP-Version을 반드시 나타내어야 한다.
HTTP/1.0 서버는,
- HTTP/0.9와 HTTP/1.0 요구를 위한 Request-Line 표현 형식을 인식할 수 있어야 하고,
- HTTP/0.9와 HTTP/1.0 형식으로 되어 있는 유효한 요구를 이해할 수 있어야 하고,
- 클라이언트가 사용한 프로토콜 버전과 같은 메시지 형식으로 적절히 응답할 수 있어야 한다.
HTTP/1.0 클라이언트는,
- HTTP/1.0 응답에 쓰이는 Status-Line의 형식을 인식할 수 있어야 하고,
- HTTP/0.9 또는 HTTP/1.0 형식으로 도착된 유효한 응답을 이해할 수 있어야 한다.
프락시나 게이트웨이 응용 프로그램은 자신의 프로토콜 버전과 다른 요구를 클라이언트로부터 수신했을 때는 이의 처리를 보다 신중하게 하여야 한다. 프로토콜 버전은 송신측 클라이언트의 프로토콜 처리 능력을 나타내는 것이므로 프락시나 게이트웨이는 송신측 버전보다 높은 메시지를 전달하면 절대 안 된다. 만약 프락시나 게이트웨의의 프로토콜 버전보다 높은 버전의 송신측 요구가 도착하면 요구한 프로토콜 버전을 낮추거나 오류를 되돌려 보내어야 한다. 만약 낮은 버전의 송신측 요구가 도착하면 중계해주기 앞서 버전을 높이는 방법도 가능하다. 해당 송신측 요구에 대한 프락시나 게이트웨이의 응답은 위에서 언급한 서버 요구사항을 만족시켜야 한다.
3.2 URI (Uniform Resource Identifiers)
URI는 현재 여러 가지 이름으로 불리우고 쓰이고 있다. 예를 들어, WWW addresses, Universal Document Identifiers, Universal Resource Identifiers 등이며, 최종적으로 URL(Uniform Resource Locators)과 URN(Uniform Resource Names)의 결합으로 정의되고 있다. 이것은 하나의 대상체에 대해 이름, 위치, 서비스, 프로토콜 등등 여러 가지 요소들을 참조할 수 있게 형식화 시킨 것이다.
3.2.1 일반적 형식
HTTP 프로토콜에 있어서의 URI란 어떤 알려진 URI에 기반하여 사용하기에 따라 절대 형식 또는 상대 형식으로 표현할 수 있는 것이다. 두 가지 요소의 차이는 표현 방법으로 구분할 수 있는데, 절대 URI 형식은 항상 scheme 이름과 뒤따르는 ":"의 표시에 의해 구분된다.
URL 형식과 의미에 관한 내용은 RFC 1738과 RFC 1808을 참조하면 된다. 위에 표시되어 있는 BNF 표현식 가운데 RFC 1738에 정의되어 있지 않은 rational이란 것이 쓰이고 있다. 이것은 rel_path 주소 부분에 쓰이는 unreserved 글자 집합에 한계가 있기 때문이다. HTTP 프락시는 RFC 1738에 정의되지 않은 URI를 가진 요구를 수신할 수도 있다.
3.2.2 http URL 형식
http 표현식은 HTTP 프로토콜을 이용하여 활용할 네트워크 자원을 지시하는 데에 쓰인다.
위 규정은 이용하고자 하는 네트워크 자원이 위치하고 있는 곳의 URL 표시를 하기 위한 것이며, port 부분에 아무런 숫자가 없다면 WWW 서비스를 위해 할당되어 있는 80번으로 인식한다.
위에 표시된 사항의 의미는 지정된 자원이 해당 host의 abs_path의 장소에 있으며, 이 서버 호스트는 지정된 port 번호에서 TCP 연결을 맺는다는 것이다. 이때 abs_path는 해당 자원에 대한 Request-URI가 되고, 만약 abs_path가 URL에 표시되어 있지 않다면 Request-URI에 사용될 때는 "/" 표시가 반드시 들어가 있어야 한다.
- [주] HTTP 프로토콜은 TCP와 같은 수송계층 프로토콜의 종류에 상관없이 쓰일 수 있는 프로토콜이다. 그러나 위와 같은 URL 표시 방식은 TCP에서나 쓰일 수 있는 것이다. 그러므로 TCP가 아닌 다른 종류의 수송계층에 HTTP가 쓰이기 위해서는 그에 맞는 URI 표현 방식을 정의하여야 한다.
http URL의 표준적인 형태는 host에 있는 UPALPHA 문자들을 해당하는 LOALPHA 문자로 변환하여 얻을 수 있다. (호스트 주소는 대소문자를 가리지 않는다.) 포트 번호가 80번이라면 [":" port]는 생략되어도 되고, abs_path가 비어있다면 "/"로 대치된다.
3.3 Date/Time 형식
HTTP/1.0 응용에서는 세 가지 형식의 일자/시간 표현 방식을 지원한다.
첫 번째 형식은 인터넷 표준으로서 쓰이는 것이며 RFC 1123에서 정의된 길이 제한에 따라 표시된다. 두 번째 형식은 통상 많이 사용되는 것이며 RFC 850의 형식을 따르고 있고 네 자리의 년도를 표시하기는 불가능한 것이다. 날짜를 해석해야 하는 HTTP/1.0 클라이언트는, 메시지를 만들 때 세 번째 표시 형식(asctime)의 날짜를 만들어서는 안 되지만, 위의 세 가지 날짜 표시 형식 모두를 인식할 수 있어야 한다.
- [주] 날짜 변수를 수신하는 측에서는, 프락시나 게이트웨이를 통해 SMTP나 NNTP를 이용하는 non-HTTP 응용 프로그램과 글을 올리거나 글을 읽어갈 수 있으므로 이때 생성되는 날짜 변수를 수용할 수 있어야 하기 때문이다.
모든 HTTP/1.0 일자/시간 사항은 예외없이 반드시 GMT 형식으로 표현되어야 한다. 앞서 두 가지 표현 형식은 GMT로서 표시되어 있으나 세 번째 형식은 생략되어 있다. 하지만 표시되어 있지 않은 asctime 형식일지라도 GMT라고 간주하도록 한다.
이것을 프로토콜 규격의 형식으로 다시 표현하면 아래와 같다.
- [주] 날짜/시간 표시 형식에 대한 HTTP 요구 사항은 프로토콜의 흐름 내에서 적용되어야 하는 것이다. 클라이언트나 서버에 있어 사용자에 대한 보이기 또는 서비스 기록 등의 용도에까지 적용할 필요는 없다.
3.4 Character SetsHTTP 프로토콜 규격서에서는 'character set'이란 용어를 MIME 규격서에서 정의한 것과 똑같이 사용한다. 즉,
- character set
- 일련의 8bit 데이타를 적절한 대응 관계에 있는 일련의 글자로 변환시킬 수 있게끔 한 개 또는 그 이상의 표로서 만들어서 참조하게 하는 수단이다. 그러므로 무조건 변환시켜서는 안 될 것이며, 모든 글자가 character set에 정의되어 있지 않을 수 있고, 특정한 글자를 표현하기 위해 하나 이상의 8bit 데이타열이 존재할 수도 있다.
이 정의에 따르면, US-ASCII와 같은 단순한 변환표로부터 ISO 2022의 경우에서와 같이 복잡한 변환표에 이르기까지 다양한 종류의 character encoding들을 허용한다. 하지만 MIME character set 이름과 관련된 정의는 8bit 데이타로부터 글자로의 변환에 관한 사항을 완전하게 명시하여야 한다. 완전한 변환 관계를 정의하기 위해 다른 수단을 통한 외부 정보를 활용해서는 안 된다.
- [주] "character set"이란 용어는 통상 "character encoding"이란 용어로서 많이 표현된다. HTTP와 MIME은 같은 등록표를 공유하기 때문에 용어 또한 공유하여 사용된다.
HTTP character set의 구분은 대소문자 구별을 하지 않는 이름으로 정해진다. 문자집합의 전체 종류들은 IANA Character Set 등록표에 정의되어 있다.[15] 그러나 이 등록표가 각각의 문자집합에 대한 단 하나의 일관된 이름을 정의하고 있는 것은 아니기 때문에, 여기서는 HTTP 엔터티와 가장 적절하게 사용될 수 있는 문자집합들에 있어서의 권고 이름들에 대해 정의하도록 한다. 이러한 문자집합들은 RFC 1521[5]에 등록되어 있는 것들을 포함하고 MIME 문자집합 파라미터에 사용되게끔 특별히 권고되는 이름들에 대해서도 포함하도록 한다.
HTTP에서는 문자집합의 종류로서 임의의 토큰 이름을 허용하고 있으므로 위에 규정되지 않은 다른 것도 사용할 수 있으나, 이것은 IANA 문자집합 등록표에 등록되어 있는 것이어야 하며, 응용 프로그램에서도 문자집합의 사용을 IANA에 등록되어 있는 것으로 한정해야 한다.
Entity-Body의 문자집합은 내용 내에 사용된 문자 코드들의 최대 공통 코드를 선정하여 표시하여야 하는데, US-ASCII나 ISO-8859-1의 경우에는 표시하지 않아도 되는 예외를 허용한다.
3.5 Content Codings
해당 자원에 대해 적용되어 있는 인코딩 변환 방식을 알리기 위해 사용한다. 이것은 실제 데이타의 화일 형식이나 내용을 손상시키지 않고 데이타를 압축하거나 보안을 위해 암호화할 때 주로 쓰일 수 있다. 이 방식으로 인코딩된 데이타가 저장되어 있다가 송수신되어 실제 활용되기 전에는 디코딩이 되어야 한다.
- [주] 향후의 적합성을 위해 HTTP/1.0 응용 프로그램에서는 "gzip"과 "compress"를 "x-gzip"과 "x-compress"로 각각 동일하게 간주하여야 한다.
표시된 모든 content-coding 변수는 대소문자를 가리지 않는다. HTTP/1.0은 Content-Encoding (10.3절 참조) 헤더 필드에 content-coding 파라미터 변수를 사용한다. 이 변수가 content-coding을 설명하는 것이긴 해도 보다 중요한 의미는 디코딩하기 위해 필요한 메카니즘이 무엇인지를 알리는 것이다. 어느 프로그램은 여러 개의 인코딩 방식을 디코딩할 수도 있다. 이 문서에서는 두 가지 인코딩 변수가 기술되어 있다.
- x-gzip
- "gzip" (GNU zip)이라는 화일 압축 프로그램에 의해 만들어진 인코딩 방식. 이것은 32-bit CRC를 이용하는 Lempel-Ziv 코딩 (LZ77) 방식이다.
- x-compress
- "compress"라는 화일 압축 프로그램에 의해 만들어진 인코딩 방식. 이것은 Lempel-Ziv-Welch 코딩 (LZW) 방식이다.
[주] 인코딩 형식을 구분하기 위해 프로그램 이름을 사용하는 것이 바람직한 것이 아니며 앞으로의 인코딩 방식 표현을 위해서도 권장할 만한 것이 아니다. 하지만 여기서는 지금까지의 활용예로 볼 때 가장 대표적인 것들을 나타낸 것이다.
3.6 Media Types
HTTP 프로토콜에서는 데이타 형식 표현의 개방성과 확장성을 위해 Content-Type 헤더 필드를 두고서 데이타 형식을 표현하고 있다. Content-Type 필드 다음에 표시될 미디어 형식 (media type)은 다음과 같은 표현식에 따른다. Content-Type 필드의 표현식은 Entity 부분에서 다시 설명된다.
파라미터는 type/subtype에 뒤이어 attribute/value의 쌍으로 구성된다.
예를 들어 다음과 같이 나타낼 수 있다.
여기서 type, subtype, 및 parameter attribute 이름은 대소문자 구분을 하지 않지만, parameter value는 파라미터 종류에 따라 대소문자를 구분할 수도 있고 구분하지 않을 수도 있다.
이러한 표현식에 있어 LWS는 type과 subtype 사이에 절대 허용되지 않으며, 또한 attribute와 이의 value 사이에도 허용되지 않는다. 인식할 수 없는 파라미터를 가진 미디어 형식이 수신되면 클라이언트는 이 파라미터가 없었던 것처럼 간주하여 처리한다.
오래 전의 일부 HTTP 구현 프로그램에서는 미디어 형식의 파라미터를 인식할 수 없었다. HTTP/1.0 구현 프로그램에서는 메시지 내용이 어떤 종류인지 지정할 필요가 있을 때만 미디어 형식의 파라미터를 사용해야 한다.
media-type의 value는 IANA[15]에 등록되어 있는 것을 사용하면 된다. 등록되어 있지 않은 것을 사용하는 것은 좋은 방법이 아니다. media-type의 등록 과정은 RFC 1590[3]에 설명되어 있다.
3.6.1 Canonicalization and Text Defaults
인터넷에서의 미디어 형식은 표준적인 형태로 (canonical form) 등록되어 있다. 통상 HTTP를 통해 전송되는 Entity-Body는 전송에 앞서 적절한 표준 형태로 표현되어야 한다. 만약 전송 내용이 Content-Encoding에 의해 인코딩되어 있다면, 실제 데이타는 인코딩되기에 앞서 표준 형태로 되어 있어야 한다.
"text" 형식인 미디어는 CRLF를 텍스트 줄바꾸기로서 사용한다. 그러나 HTTP에서는 CR 또는 LF 하나만 있어도 Entity-Body 내에서 일관되게 사용될 때는 텍스트 미디어의 전송에 있어 줄바꿈 표시로서 허용한다. 따라서 HTTP 응용 프로그램은 HTTP를 통해 수신한 text 미디어의 줄바꿈의 표시로서 CRLF와 CR 및 LF의 단독 사용을 허용하여야 한다.
만약 CR 및 LF를 위한 octets 13과 10을 사용하지 않는 문자집합으로 텍스트 미디어가 표현되어 있다면, HTTP는 줄바꾸기 표시로서 CR 및 LF의 의미로 할당되어 있는 다른 octet 표시를 사용할 수 있어야 한다. 이러한 융통성은 Entity-Body에 있는 텍스트 미디어에 대해서만 적용한다. CR 또는 LF의 단독 사용은 헤더 필드와 같은 HTTP 제어 부분 내에서는 CRLF 대신으로 쓰여서는 안 된다.
"charset" 파라미터는 데이타의 문자집합(3.4절 참조)을 정의하기 위해 미디어 종류와 함께 쓰인다. 만약 송신측이 분명한 문자집합 파라미터를 전달하지 않는다면, HTTP를 통해 데이타를 수신할 때 "text"인 subtype에 "ISO-8859-1"인 문자집합이라고 기본적으로 간주한다. 만약 "ISO-8859-1" 또는 이의 서브셋 이외의 문자집합으로 표현되어 있는 데이타라면 수신측에서 일관성 있게 해석될 수 있도록 하기 위해 적절한 문자집합 이름으로 표현되어 있어야 한다.
- [주] 현재의 많은 HTTP 서버들이 적절한 이름 표시 없이 "ISO-8859-1" 이외의 문자집합을 사용하여 데이타를 보내고 있다. 이것은 클라이언트와 서버와의 상호운용성을 떨어뜨리는 요소가 되고 권장할 바가 아니다. 이 문제를 해결하기 위해 일부 HTTP 사용자 에이전트는 문자집합 파라미터가 없을 때 사용자에게 기본 설정을 변경시킬 수 있도록 클라이언트 환경을 재구성하게 만들기도 한다.
3.6.2 Multipart Types
MIME은 "multipart" 형식을 제공하는데, 하나의 메시지에 있는 Entity-Body 속에 여러 개의 엔터티를 포함할 수 있도록 한다는 말이다. IANA에 등록되어 있는 multipart 형식들은 HTTP/1.0에 대해 특별한 의미를 부여하지 않는다. 하지만 사용자 에이전트들은 각각의 엔터티 요소들을 적절히 인식하기 위해 각 미디어 형식을 이해해야 할 필요가 있다. 따라서 HTTP 사용자 에이전트는 MIME 사용자 에이전트가 multipart 형식을 수신하자 마자 동작하는 것과 똑같이 또는 비슷하게 동작하여 처리하여야 한다. HTTP 서버는 모든 HTTP 클라이언트가 multipart 형식을 처리할 수 있다고 가정하지 않아야 한다.
모든 multipart 형식은 공통의 표현식을 사용하고 있으며, 미디어 형식 변수의 일부분으로서 경계 파라미터를 갖고 있어야 한다. 메시지의 데이타 내용은 그 자체로서 하나의 프로토콜 요소이며, multipart에 있어서의 각 엔터티 사이의 줄바꾸기를 표현하기 위해 CRLF만 사용하여야 한다. 각각의 엔터티 부분은 해당 부분에 있어서 의미를 갖는 HTTP 헤더 필드를 포함할 수도 있다.
3.7 Product Tokens
사용하고 있는 응용 프로그램에 대한 정보를 알려주기 위해 쓰이는데, 간단한 상품 이름으로서 표현을 하며 선택적으로 "/"와 버전 표시가 함께 들어갈 수도 있다. 빈 공백 표시(whitespace)를 이용하여 해당 응용 프로그램의 주요 부분에 대한 정보를 연이어서 표시할 수도 있다. 그러므로 중요도가 가장 높은 사항을 먼저 표시하고 뒤 이어서 다른 사항들을 표시하도록 한다.
이에 의한 예를 들어보면 아래와 같다.
또 다른 예로서,
이러한 것을 볼 수 있다.
이와 같은 프로그램 정보를 표시할 때는 간단하게 핵심 사항만 나타나게 하여야 하며, 제품 선전이나 중요하지 않는 사항을 알린다든지 하는 것은 허용되지 않는다. 그리고 product-version의 자리에는 어떤 종류의 글자가 오더라도 상관이 없으나, 반드시 버전을 나타내어 같은 프로그램의 개량 종류를 구분할 수 있도록 하여야 한다.
4. HTTP Message
4.1 HTTP 메시지 종류
HTTP 프로토콜의 동작을 위해 존재하는 메시지는 클라이언트로부터 서버로 보내는 요구 (request) 메시지와 반대로 서버에서 클라이언트로 보내는 응답 (response) 메시지로 구성되고, 이것은 모두 네 가지 종류로 해서 구분된다.
두 가지는 예전의 0.9 버전의 프로토콜에서 쓰이던 것이고 나머지 두 가지는 현재의 1.0 버전 프로토콜에서 쓰이는 것이다. 이에 대한 표현 형식이 아래와 같다.
Full-Request와 Full-Response는 데이타 송수신을 위해 RFC 822에서 정의하고 있는 메시지 형식을 사용한다. 각 메시지 형식은 선택 가능한 헤더 필드와 실제 데이타 부분인 하나의 Entity-Body로 구성되어 있다. Entity-Body는 헤더 부분과의 구분을 하나의 빈 줄로서 하고 있다. 즉, CRLF 앞에 아무 것도 없는 공백 줄을 말한다.
브라우저가 서버에게 문서 요청을 할 때, 브라우저가 사용하고 있는 프로토콜 버전에 따라서 Simple-Request 형식이나 Full-Request 형식이나 둘 중 하나를 만들어서 요구하게 된다. 그러면 서버는 브라우저가 요구한 프로토콜 버전에 따라서 이에 대한 응답으로 Simple-Response나 Full-Response 형식의 응답을 전달한다.
이러한 메시지는 응용 프로토콜 레벨에서 만들어지는 것이므로 실제로 인터넷을 통해 전달될 때는 추가적인 과정이 더 존재하게 된다. 먼저 브라우저는 문서 요구를 위한 HTTP 요구 메시지를 위에 정의에 따라 만들고, 이것은 TCP/IP 프로토콜을 기반으로 하는 인터넷을 통해 전달되어야 하므로, TCP 프로토콜에서는 위에서 만든 메시지 앞에다 TCP 프로토콜을 위한 헤더를 추가하고, 그 다음 단계인 IP 프로토콜에서 IP 프로토콜을 위한 헤더를 앞 부분에 추가해서 보내게 된다.
IP 프로토콜에서 만들어진 헤더는 인터넷을 여행하는 가운데 중간 경로상의 라우터에서 목적지까지의 경로를 찾기 위해 참조가 되고, TCP 프로토콜에서 만들어진 헤더는 목적지에 도착해서 속에 든 HTTP 메시지에 데이타 손상과 같은 문제가 없이 제대로 도착했는지 확인해보기 위해 쓰이게 된다.
그런 다음에 HTTP 프로토콜이 HTTP 메시지를 해석하고 이에 따라 서버는 적절하게 동작한다. 이렇게 동작한 결과를 HTTP 응답 메시지로 만들고 위에서 설명한 과정을 똑같이 거쳐 최초에 요구한 브라우저로 전달된다.
따라서 HTTP 프로토콜이 어떻게 구성되어 있는지 알고자 한다면 위 네 가지 메시지의 구성 형식을 살펴보면 되는 것이다. 이것이 HTTP 프로토콜의 모든 것이다.
4.1.1 HTTP/0.9 메시지 형식
0.9 버전에서의 HTTP 메시지 형식은 아래와 같이 단순하게 되어 있다. 여기서는 어떤 종류의 헤더 정보도 허용되지 않으며, 단지 요구 방법으로서 GET이란 request method가 쓰이고, 이에 대한 요구 문서의 URI가 표현될 뿐이다.
이러한 0.9 버전의 HTTP 프로토콜 요구/응답에서 사용할 수 있는 method 는 GET 하나 뿐이다. 그러므로 브라우저는 서버에게 문서를 보내 달라고 하는 요청만 가능하며 서버에게 문서를 올리거나 지우거나 하는 기능은 불가능하다. GET을 통해 문서를 요청하면서 해당하는 문서의 URI를 지정해야 할 것이며 이것이 Request-URI에 해당한다. 이러한 요청에 따른 응답이 Entity-Body로서 실려오게 된다. 이때 전달되는 문서의 media type이 표시될 수 없기 때문에 Simple-Request 형식의 사용은 지양해야 한다.
4.1.2 HTTP/1.0 메시지 형식
HTTP/1.0 버전에서는 0.9 버전에 비해 더욱 다양한 기능들을 제공한다. 이에 따라 메시지 구성 형식은 훨씬 더 복잡한 형태를 띠고 있다.
위에서 Full-Request의 예를 들자면 이와 같은 표현 방식에 의해 다음과 같은 예들이 가능함을 알 수 있다.
Full-Response의 경우도 마찬가지로 살펴볼 수 있다.
각 경우에서 보듯이 Entity-Body는 CRLF 에 의해 공백 줄이 추가되어 구분되고 있다.
4.2 메시지 헤더 (Message Headers)
앞서 메시지 필드들에 보면, General-Header (4.3절 참조), Request-Header (4.4절 참조), Response-Header (4.5절 참조), Entity-Header (4.6절 참조) 등과 같이 네 가지 헤더 형식이 있다. 여기에서 공통적으로 사용하는 표현 형식은 RFC 822의 3.1절에서 정의하고 있는 것이다.
이러한 헤더의 순서는 중요하지 않으나 가능하다면 General-Header가 먼저 나오고 이어서 Request-Header 또는 Response-Header가 나오고 그 다음에 Entity-Header 필드가 나오는 것이 좋다. 각 헤더 필드는 이름과 뒤이은 ":", 한 개짜리 빈칸 (single space, SP), 그리고 필드의 value로 구성된다. 필드의 이름은 대소문자를 가리지 않는다. 헤더 필드는, 권장하는 것은 아니지만, 적어도 한 개의 SP 또는 HT 표시를 통해 줄 바꾸기 하여 여러 줄로 표시할 수 있다.
field-value가 #(values)와 같은 방식에 의해 ","로 구분되는 여러 개 values로서 표현된다면 같은 field-name을 가진 여러 개의 HTTP-header 필드로 표현될 수 있다. 이 경우에는 반드시 여러 개의 헤더 필드를 하나의 "field-name:field-value"의 쌍으로 결합할 수 있어야 하고, 메시지의 목적을 변경시켜서는 안 된다. 이러한 각각의 쌍은 ","에 의해 구분되어 처음의 것에 뒤이어 결합되어야 한다.
4.3 일반 헤더 필드 (General Header Fields)
일반 헤더는 Full-Request 메시지와 Full-Response 메시지에 공통적으로 포함되어 있는 헤더 형식이다. 이것은 전송되고 있는 메시지에 관한 사항을 알리는 것이지, 전송되고 있는 사용자 데이타에 관한 사항을 알리는 것이 아니다.
필드 이름은 HTTP 프로토콜의 버전 변경과 함께 프로토콜의 확장을 꾀할 때 추가될 수 있다. 그러나 이렇게 확장되는 필드는 일반 헤더 필드가 가진 역할에 적합해야 할 것이다. 인식할 수 없는 헤더 필드는 Entity-Header 필드로서 간주한다.
위의 헤더 형식을 풀어서 다시 살펴보면 아래와 같이 나타내 보일 수 있다.
4.4 요구 헤더 필드 (Request Header Fields)
Request-Header 필드는 Full-Request 메시지에 포함되는 것이며, 요구 사항에 대한 또는 클라이언트 자체에 대한 추가적인 정보를 서버에게 전달할 때 쓰인다.
Request-Header의 필드 이름은 HTTP 프로토콜의 버전 변경과 함께 프로토콜의 확장을 꾀할 때 추가될 수 있다. 그러나 이렇게 확장되는 필드는 요구 헤더 필드가 가진 역할에 적합해야 할 것이다. 인식할 수 없는 헤더 필드는 Entity-Header 필드로서 간주한다.
이것을 보다 상세히 풀어서 나타내면 아래와 같다.
4.5 응답 헤더 필드 (Response Header Fields)
응답 헤더 필드는 서버가 응답 메시지를 보낼 때 Status-Line에다 실을 수 없는 추가적인 정보를 전달하고자 할 때 쓰인다. 서버는 이것을 이용하여 서버 자신에 대한 정보나 Request-URI에서 명시한 자원에 대한 접근 및 이용 방법에 대한 정보를 전달할 수 있다. 다음과 같은 표현식으로 나타낸다.
Response-Header의 필드 이름은 HTTP 프로토콜의 버전 변경과 함께 프로토콜의 확장을 꾀할 때 추가될 수 있다. 그러나 이렇게 확장되는 필드는 응답 헤더 필드가 가진 역할에 적합해야 할 것이다. 인식할 수 없는 헤더 필드는 Entity-Header 필드로서 간주한다.
이것을 보다 상세히 풀어서 나타내면 아래와 같다.
4.6 엔터티 헤더 필드 (Entity Header Fields)
Entity-Header 필드는 Entity-Body에 대한 인코딩 방식, 최종 수정 일자, 유효 기간, 문서 길이 등과 같은 외형적 정보(metainformation)를 나타낼 때 쓰이거나, 전달할 entity body 데이타가 없을 때는 요구 메시지에서 지정한 해당 자원에 대한 정보를 알려줄 때 쓰인다.
extension-header 필드는 프로토콜을 수정하지 않더라도 추가적인 Entity-Header 필드를 정의하도록 쓰일 수 있다. 그러나 수신측에서 이것이 Entity-Header의 의미로서 해석되어서는 안 된다. 인식할 수 없는 헤더 필드는 수신측이 무시하거나 프락시가 다른 곳으로 중계하여야 한다.
이것을 풀어서 보다 상세히 나타내면 아래와 같다.
5. Request
사용자의 요구 사항을 받은 클라이언트가 HTTP 프로토콜에 따라서 서버에게 요구 사항을 전달할 때 아래에 정의되어 있는 요구 메시지가 사용된다. 이러한 요구 메시지는 프로토콜의 버전에 따라서 두 가지 종류가 있음을 앞서 4.1절에서 보였으며 Simple-Request와 Full-Request가 바로 그것이다.
Full-Request 메시지의 구성 형식을 앞서 4.1.2절에서 살펴보았으며, 이 가운데 General-Header의 형식은 4.3절에서 살펴보았고 Entity-Header는 4.6절에서 살펴보았다. 여기서는 Full-Request 메시지와 관련해서 나머지 헤더와 형식을 살펴보기로 한다.
클라이언트에서 서버로 전달되는 요구 메시지의 첫 번째 줄에 원하는 해당 자원에 적용할 이용 방법 (method), 자원의 위치와 같은 정보, 및 사용하고 있는 프로토콜 버전 등이 포함된다. HTTP/0.9 버전의 프로토콜과도 동작하기 위해 요구 메시지는 Simple-Request와 Full-Request의 두 가지 종류로서 표시된다.
요구 메시지의 형식을 다음과 같이 나타내 보일 수 있다.
HTTP/1.0 서버가 Simple-Request를 수신하여 응답할 때는 반드시 HTTP/0.9 형식의 Simple-Response 형식으로 응답하여야 한다. Full-Response를 수신할 수 있는 HTTP/1.0 클라이언트는 절대 Simple-Request를 보내지 않아야 한다.
5.1 Request-Line
요구 메시지에 들어가는 첫 번째 줄의 첫 순서 내용이 Request-Line이며 아래와 같은 구성 형식으로 되어 있다. Request-Line은 자원의 이용 방법 (method), 해당 자원의 위치를 가리키는 Request-URI, 프로토콜 버전, 그리고 마지막에 CRLF로서 표시된다. 각각의 파라미터들은 SP에 의해 구분되고 있다.
메시지 정보의 끝을 나타내는 CRLF은 마지막 이외의 장소에서는 허용되지 않는다. 다만 사용자 정보 데이타와 같은 Entity-Body 부분은 CRLF에 뒤이어 나타날 수 있다. 따라서 실제 사용자 데이타를 보내기 위해서는 메시지 정보 다음에 공백의 빈줄을 반드시 집어 넣어야 인식할 수 있다.
보다 상세하게 풀어서 나타내면 아래와 같다.
Full-Request 속에 있는 Request-Line과 Simple-Request의 차이점은 HTTP-Version 필드의 존재 유무와 GET 이외의 다른 방법을 지정할 수 있는지 없는지 하는 것이다.
5.1.1 Method
Request-URI로 지정되는 대상체에 대해 어떻게 활용할 것인지 그 이용 방법을 지정한다. 예를 들어 GET으로 지정되어 있으면 Request-URI로 지정되어 있는 데이타 화일을 가지고 오라는 뜻이 되며, POST로 지정되어 있으면 Request-URI로 지정되어 있는 장소에 Entity-Body로 전달되는 글을 올릴 수 있다. 현재 세 가지 종류가 정의되어 쓰이고 있으며 다음과 같다.
다음과 같은 표시 형식으로 나타낼 수 있고, 대소문자를 가리지 않는다.
GET, HEAD, POST라고 하는 세 가지 Method에 대한 설명은 8장에서 이루어질 것이다.
클라이언트가 대상 자원에 대해 요청한 것이 서버에서 처리할 수 없는 것이라면 서버는 501 (not implemented) 상태 정보를 되돌려 준다.
5.1.2 Request-URI
요구 메시지에 있는 Method에 의해 지정되는 동작을 어느 장소에 있는 대상에게 적용할 것인지 나타낸다. 이렇게 표시되는 URI는 다양한 정보를 함축하고 있으며 3.2절을 참조하면 된다. 다음과 같은 표시 형식으로 나타낼 수 있다.
absoluteURI 형식은 요구 메시지가 프락시 서버로 전달될 때에만 쓰인다. 프락시는 수신한 요구 메시지를 중계하고 전달받은 응답 메시지를 최초 요구한 클라이언트에게 전달한다. 요구 메시지가 GET 또는 HEAD이고 해당 요구에 대한 이전 응답이 이미 캐시되어 있다면 Expires 제한 조건에 위배되지 않는 한 이미 캐시되어 있는 응답 메시지를 그대로 전달한다. 여기서 Expires는 캐시되어 있는 정보에 대한 유효 기간을 지정한 것이다.
프락시는 수신한 요구 메시지를 다른 프락시로 중계할 수도 있으며, 또는 absoluteURI에서 지정한 서버로 곧바로 중계해줄 수도 있다. 이때 요구 메시지의 루핑(looping)을 방지하기 위해 프락시는 자신의 모든 서버 이름과 IP 주소를 인식하고 있어야 하며, 이때의 서버 이름에는 alias 이름이나 호스트 내부에 설정되어 있는 별명까지도 포함된다.
한 가지 예는 다음과 같다.
Request-URI의 가장 일반적인 형태는 프락시 서버가 아닌 호스트 서버에 있는 자원을 지정할 때 쓰이는 것이며, 이 경우에는 URI의 abs_path (3.2.1절 참조) 부분만이 전달된다. 예를 들어, 호스트 서버로부터 위에 명시한 문서를 클라이언트가 직접 가져오고자 하는 경우, www.w3.org 호스트에 80번 포트로 TCP 연결을 맺어 다음과 같은 내용을 보낸다.
위에 이어서 Full-Request의 나머지 부분이 뒤따른다. 여기서 위 루트 경로 표시는 절대 생략되어서는 안 된다. 따라서 만약에 원래 URI에 아무 것도 지정되어 있지 않다면 Request-URI에 "/" 이 표시가 들어가야 한다. 예를 들어, http://pec.etri.re.kr과 같은 URL로 사용자가 요구하였다면 경로 표시가 되어 있지 않으므로, 아래와 같이 "/"가 추가되어 Request-URI가 구성된다.
만약 http://www.w3.org/ 이와 같은 URL을 지정했을 때는 루트 경로가 "/"로서 이미 표시되어 있으므로 당연히 위와 같은 표현식이 된다. 즉, 결과적으로는 두 가지 경우에 대한 Request-URI 표현식이 똑 같다.
Request-URI가 전송될 때는 인코딩되어 전달된다. 여기서 몇 가지 글자는 RFC 1738에서 정의하고 있는 "%HEX HEX" 인코딩 방식으로 변환될 수 있다. 수신하는 서버는 요구 메시지를 적절히 처리하기 위하여 인코딩되어 있는 Request-URI를 디코딩할 수 있어야 한다.
5.2 요구 헤더 필드 (Request Header Fields)
4.4절을 참조하면 된다.
6. Response
서버는 수신한 요구 메시지를 HTTP 프로토콜에 맞게 번역하여 적절한 동작을 수행하고 프로토콜의 응답 메시지 형식에 맞춰 결과를 전달한다. 응답 메시지의 형식을 다음과 같이 나타내 보일 수 있다.
이러한 응답 메시지는 프로토콜의 버전에 따라서 두 가지 종류가 있음을 4.1절에서 보였으며 Simple-Response와 Full-Response가 그것이다. Simple-Response는 HTTP/0.9 프로토콜 형식의 요구 메시지에 대한 응답, 또는 서버가 HTTP/0.9 프로토콜로 제한적으로 쓰일 때의 응답으로만 사용되어야 한다.
클라이언트가 HTTP/1.0 형식의 Full-Request를 보냈는데 수신한 응답이 Status-Line으로 시작하지 않는다면, 수신한 응답이 Simple-Request라고 간주하고 적절하게 해석 처리를 하도록 한다.
Full-Response의 각 헤더 필드들은 4.2절에서 이미 살펴보았다.
6.1 Status-Line
Full-Response 메시지에 들어가는 첫 번째 줄의 내용이 Status-Line이며 아래와 같은 구성 형식으로 되어 있다. 각각의 파라미터들은 SP에 의해 구분되고 있으며, HTTP 버전이 제일 먼저 나오고 이어서 숫자로 된 상태 코드가 표시되고 이어서 관련된 추가적인 내용 설명이 덧붙여진다. 메시지 정보의 끝을 나타내는 CRLF는 마지막 이외의 장소에는 허용되지 않는다. 다만 사용자 데이타와 같은 엔터티 부분은 CRLF에 뒤이어 나타날 수 있다. 따라서 실제 사용자 데이타를 보내기 위해서는 메시지 정보 다음에 공백의 빈줄을 반드시 집어넣어야 인식할 수 있다.
보다 상세하게 풀어서 나타내면 아래와 같다.
이러한 상태 표시줄은 항상 다음과 같은 프로토콜 버전과 상태코드로 시작하기 때문에,
(예, "HTTP/1.0 200 "), 이 표현식을 통해 충분히 Simple-Response와 Full-Response를 구분할 수 있다. Simple-Response의 형식은 Entity-Body의 첫 부분에 위와 같은 표현식을 포함할 수도 있고, 이 때문에 Full-Request의 응답으로 전달되는 것이라면 충분히 잘못 해석될 수 있다. 그래서 대부분의 HTTP/0.9 서버에서는 "text/html" 형식의 응답만 하도록 제한하고 있으며, 앞서 언급한 오해는 절대 발생하지 않는다.
6.1.1 Status-Code와 Reason-Phrase
상태코드는 서버가 요구 메시지를 수신하여 처리한 결과를 알려주는 세 자리의 정수로 된 처리 결과 번호이다. Reason-Phrase에는 Status-Code에 대한 짤막한 설명문이 들어갈 수 있다. 상태코드는 오토마타가 사용하도록 하는 것이고, 이유 설명문은 사용자에게 상태 정보를 글로써 알리기 위한 것이다. 클라이언트는 이러한 Reason-Phrase를 검사해 보거나 화면에 보이게 할 필요는 없다.
첫 번째 자리 숫자는 응답의 종류에 대한 분류 기호이며, 나머지 두 자리 숫자는 일련번호이다. 현재 첫 번째 자리 숫자에 대해 다섯 가지로 분류하여 쓰고 있다.
- 1xx : Informatinal - 향후의 사용을 위해 예약. 아직 사용되지 않음.
- 2xx : Success - 성공적으로 수신되고 해독되고 처리된 경우.
- 3xx : Redirection - 완전한 처리를 위해 추가적인 동작이 필요로 하는 경우.
- 4xx : Client Error - 요구 메시지에 글자상의 문제가 있는 경우거나 메시지를 처리할 수 없을 때.
- 5xx : Server Error - 서버가 요구 메시지를 처리하는 가운데 문제가 발생한 경우.
HTTP/1.0에서 정의한 상태 코드와 대응하는 Reason-Phrase 설명문을 아래의 예에서 볼 수 있다. 여기서의 설명문은 단지 권장 사항일 뿐이며, 같은 의미에 있어 다른 글로서 표현해도 된다. 각 상태코드에 대한 상세 설명은 9장에 있다.
HTTP 상태코드는 확장이 가능한데, 위 코드들은 현재 일반적으로 사용되는 것들이다. HTTP 응용 프로그램에서는 등록되어 있는 모든 상태코드의 의미를 알아야 할 필요는 없지만 그래도 권장 사항이며, 첫번째 숫자로 표시되는 클래스 분류에 있어서는 반드시 알아야 한다. 인식할 수 없는 상태코드인 경우에는 해당 클래스의 x00 상태코드로 간주하도록 하고, 이것은 절대 캐시되어서는 안 된다.
예를 들어, 431이라는 인식할 수 없는 상태코드가 클라이언트에게 수신되었다면 요구 메시지에 무언가 문제가 있었던 것이라고 가정을 하고 400번 상태코드가 수신된 것으로 간주하도록 한다. 이 경우에 사용자 에이전트는 사용자에게 응답과 함께 돌아온 엔터티 내용을 보여주도록 한다. 왜냐하면 비정상적인 상황에 대한 설명이 사람이 읽을 수 있는 형태로 엔터티 속에 포함되어 있을 것이기 때문이다.
6.2 응답 헤더 필드 (Response Header Fields)
4.5절에 설명되어 있다.
7. 엔터티 (Entity)
Full-Request와 Full-Response 메시지는 각 메시지 내에 문서나 사용자 데이타와 같은 엔터티 요소를 전송할 수 있다. 이러한 엔터티는 Entity-Header 필드와 Entity-Body로서 구성된다. 7장의 설명에 있어서 클라이언트와 서버는 엔터티 요소를 전송하느냐 수신하느냐에 따라 각각 송신자 또는 수신자가 될 수 있다.
7.1 엔터티 헤더 필드 (Entity Header Fields)
4.6절에 설명되어 있다.
7.2 Entity Body
HTTP 요구 또는 응답 메시지에 포함되어 전달되는 entity body는 Entity-Header 필드에 의해 정의되는 형식과 인코딩 방식으로 구성되어 전달된다. Entity-Body는 다음과 같은 단순한 형식이다.
요구 메시지에 entity body가 존재한다는 것은 요구 메시지 헤더의 Content-Length 필드의 존재를 보고서도 알 수 있다. 즉, entity body를 포함하는 HTTP/1.0 요구 메시지는 반드시 Content-Length 헤더 필드를 포함해야 한다는 뜻이기도 하다.
entity body가 응답 메시지에 포함될지 안 될지는 요구 메시지와 이에 대한 결과 코드에 의해 좌우된다. HEAD method가 지정된 요구 메시지에 대한 모든 응답에는 entity body가 포함되어서는 안 된다. 그리고 1xx(informational), 204(no content), 304(not modified) 응답에도 entity body가 포함되어서는 안 된다. 이외의 다른 모든 응답에는 entity body가 포함되거나 Content-Length 헤더 필드에 '0'의 값이 들어가야 한다.
7.2.1 Type
메시지에 Entity-Body가 포함되어 있을 때, 이에 대한 데이타 형식은 Content-Type과 Content-Encoding 헤더 필드를 통해 결정할 수 있다. 이는 두 개의 계층으로 된 순차 인코딩 모델 (ordered encoding model)로서 정의될 수 있다. 즉,
여기서 Content-Type은 하위 데이타의 미디어 형식을 지정하고, Content-Encoding은 통상 데이타 압축의 용도로서 해당 형식에 적용되는 어떤 추가적인 인코딩 방식을 표시하기 위해 사용된다. 이것은 요청받은 자원에 대한 특성의 표시란 의미를 가지게 된다. 이러한 인코딩 방식의 기본 설정은 아무 것도 없는 것이다.
entity body를 포함하고 있는 어떤 HTTP/1.0 메시지이든 이의 미디어 형식을 표시하는 Content-Type 헤더 필드를 포함하고 있어야 한다. Simple-Response의 경우처럼 만약 Content-Type 헤더에 의해 주어지지 않는 경우라면 수신측은 데이타 내용과 URL에 있는 화일 이름의 확장명을 이용하여 추측할 수도 있다. 그래도 알 수가 없다면 수신측에서는 이것을 "application/octet-stream"으로 간주하도록 한다.
7.2.2 Length
Entity-Body가 메시지 속에 포함되어 있을 때 이의 길이를 하나 또는 두 가지 방식으로 결정할 수 있다. 만약 Content-Length 헤더 필드가 존재한다면, 바이트 단위의 크기가 해당 길이를 표시할 수 있다. 그렇지 않은 경우라면, 서버가 연결을 해제할 때 결정될 수 있다.
연결의 해제가 요구 메시지의 Entity-Body의 끝을 의미할 수는 없다. 왜냐하면 서버가 응답을 돌려보내지 않을 가능성이 있기 때문이다. 그러므로 엔터티를 포함하고 있는 HTTP/1.0 요구 메시지는 반드시 유효한 Content-Length 헤더 필드를 갖고 있어야 한다. 만약 요구 메시지가 엔터티를 갖고 있으나 Content-Length가 명시되어 있지 않고, 서버가 다른 필드로부터 길이를 인식할 수 없고 계산도 할 수 없다면, 서버는 400 (bad request)를 보내어야 한다.
8. Method 정의
HTTP/1.0 프로토콜에는 요구 메시지에 지정하는 대상에 대한 활용 방법에 대한 표시를 하도록 되어 있는데 method라고 하는 것이다. 즉, 지정한 Request-URI에 대해 보내달라고 전송 요청 (GET) 할지, 서버에 전달하고자 (POST) 할지, 해당 문서의 헤드 정보 (HEAD) 만을 전송 요청 할지, 이에 대한 활용 방법을 지정하는 것이다.
위 세 가지 method 종류 이외에 추가할 수도 있지만, 추가적인 기능 구현의 클라이언트와 서버를 위해 같은 역할을 하는 다른 이름으로 method를 만들 수는 없다.
8.1 GET
GET method는 Request-URI에서 지정한 어떤 정보이든지 entity body로서 전달해 달라고 요청하는 의미로서 쓰인다. Request-URI가 어떤 실행 프로그램을 명시하는 경우에는 실행 프로그램 자체가 전달되는 것이 아니라 실행된 결과가 응답 메시지의 entity body로서 전달된다.
요구 메시지에 If-Modified-Since 헤더 필드가 포함되어 있다면 GET은 조건부 GET으로도 동작할 수 있다. 이 경우의 GET이 가지는 의미는, 지정된 자원이 If-Modified-Since에 의해 지정된 일자 이후에 수정된 것일 경우에만 전송하라는 것이다. 이 조건을 이용하여 불필요한 데이타 전송을 막을 수 있고 이미 캐시되어 있는 데이타를 사용자에게 전달해줌으로써 네트워크의 활용성을 높일 수 있다.
8.2 HEAD
HEAD method는, 응답 메시지의 Entity-Body에 어떤 내용도 실어 보내서는 안 된다는 점을 제외하고는 GET method와 똑같다. HEAD 요구 메시지에 대한 응답으로 HTTP 헤더에 포함되는 데이타 형태 정보는 (metainformation, 4.6절 참조) GET 요구에 대한 응답으로 전달되는 정보와 동일해야 한다. 이러한 HEAD method는 Request-URI에 의해 지정되는 자원에 대해 Entity-Body에 실제 내용을 가져오지 않더라도 자원에 대한 외형 정보 (metainformation) 획득을 위해 사용할 수 있다. 이것을 활용하여 자원에 대한 유효성, 접근성, 최근 수정 정보 등에 대한 검사를 수행할 수 있다.
여기서 조건부 GET과 비슷한 조건부 HEAD 동작은 허용하지 않는다. 따라서 If-Modified-Since 헤더 필드가 HEAD 요구 메시지에 포함된다면 무시하도록 해야 한다.
8.3 POST
POST 요구 메시지는 메시지의 entity body에 포함되어 있는 자원을 Request-Line에 있는 Request-URI에 지정되어 있는 대로 서버에서 수용해달라고 요청할 때 쓰인다. 즉, POST는 다음과 같은 기능을 수행하기 위한 한 가지 방법으로 설계되었다.
- 기존 문서에 주석을 붙일 때
- BBS 게시판, 메일링 리스트, 뉴스그룹, 또는 글 모음 장소 등에 글을 올릴 때
- 어떤 프로그램의 실행을 위해 form과 같은 특정 규격의 데이타를 넘겨줄 때
- 부가적인 동작을 통해 데이타베이스를 확장하고자 할 때
POST method에 의해 수행되는 실제 동작은 서버에 의해 결정되고 통상 Request-URI에 의해 좌우된다. 포스팅되는 대상은, 하나의 화일이 어느 디렉토리에 자리하게 되고 뉴스가 포스팅되는 뉴스그룹에 올려지고 레코드가 데이타 베이스가 등록되는 등과 똑같은 방식으로 지정된 URI에 놓이게 된다.
POST는 대상 서버에 하나의 자원으로서 생성될 필요가 없고 추후의 참조를 위해 접근 가능해야 할 필요도 없다. 즉, POST method에 의해 수행되는 동작은 포스팅 되는 entity가 URI에 의해 지정될 수 있는 자원이 아니어도 된다는 것이다. 이 경우의 적절한 응답 결과 코드는 200 (ok) 또는 204 (no content)가 될 것인데, 응답 메시지에 entity가 포함되어 있느냐 있지 않느냐에 따라 구분이 될 것이다. 어떤 자원이 대상 서버에 생성되는 경우라면 응답 결과 코드는 201(created)이 되어야 하고 상태 정보나 생성된 새 자원에 대한 정보를 알려주는 entity가 포함되어 있어야 한다.
HTTP/1.0의 모든 POST 요구 메시지에는 Content-Length가 반드시 있어야 하며, 서버가 이에 대한 정보를 확보하지 못하게 되면 400(bad request) 메시지를 응답해야 한다.
응용 프로그램에서는 POST 요구 메시지에 대한 응답을 캐싱할 필요가 없다. 왜냐하면 서버가 추후의 요구 메시지에 대한 응답으로서 똑같은 응답을 할 것인지 알 수가 없기 때문이다.
9. 상태 코드 정의 (Status Code Definitions)
상태 코드에는 다음과 같은 것들이 존재하는데, 응답 메시지에 포함되는 외형정보 (metainformation)와 해당 상태코드를 일으킬 수 있는 method에 대한 설명도 함께 하도록 한다.
9.1 Informational 1xx
이 상태코드 클래스는 임시적인 응답을 의미하며 Status-Line과 선택적인 헤더들로 구성되어 빈줄로서 끝을 나타낸다. HTTP/1.0에서는 이 클래스에 해당하는 어떤 상태코드도 아직 정의하지 않고 있으며 HTTP/1.0 요구에 대한 유효한 응답으로서 인정하지도 않는다. 그러나 이 프로토콜 규약에서 벗어나는 목적을 위한 실험적인 용도로는 활용할 수 있다.
9.2 Successful 2xx
이 클래스의 상태코드는 클라이언트의 요구가 성공적으로 수신되어 처리되었다는 것을 의미한다.
- 200 OK
- 클라이언트의 요구가 서버에서 성공적으로 처리되었음을 표시한다. 응답과 함께 돌아오는 정보는 요구 메시지에 사용된 method에 따라 틀리다. 즉,
GET - 요청받은 자원이 응답 속에 엔터티로 전달된다.
HEAD - 응답은 Entity-Body가 아니라 헤더 정보를 갖고 있어야 한다.
POST - 동작의 결과를 설명하거나 포함하는 엔터티. - 201 Created
- 요구 메시지가 처리되었으며 이로써 새로운 자원이 생성되었다는 것을 의미한다. 새로 생성된 자원은 응답 메시지의 엔터티를 통해 전달된 URI에 의해 참조될 수도 있으며 반드시 이렇게 되어야 할 필요는 없다. 원서버에서는 Status-Code를 만들기 전에 자원을 생성하여야 하며, 해당 동작을 서버가 즉시 수행할 수 없다면 서버는 언제 해당 자원을 이용할 수 있는지 알림 사항을 응답 메시지에 포함시켜야 한다. 그렇지 않다면, 서버는 202 (accepted) 응답을 보내어야 한다. POST만이 이 동작을 실행시킬 수 있다.
- 202 Accepted
- 요구 메시지를 수신하여 처리하고 있지만 아직 완료되지 않은 상태다. 이 요구는 실제로 처리 완료될 수도 있고 실패할 수도 있는데, 실제 처리를 하고자 할 때 허용되지 않는 동작일 수 있기 때문이다. 이와 같은 경우에 별도의 상태코드를 다시 전달할 수는 없다.
202 응답은 의도적으로 전달하지 않도록 한다. 이의 목적은 하루에 한 번만 동작해야 하는 처리 사항이 있을 때 사용자 에이전트가 이 처리가 완료될 때까지 서버와 연결을 맺고서 기다리지 않아도 되게끔 하기 위해서인데, 서버에게 이 동작을 위해 일단 요구 메시지를 수신하도록 하고 202 응답을 보내고 연결을 해제하도록 한다. 수신된 요구는 적절한 때에 동작 완료될 수도 실패할 수도 있다. 이 응답과 함께 돌아오는 엔터티에는 요구의 현재 상태에 대해 인식했다는 정보가 들어가 있어야 하고, 상태 모니터에 대한 포인터나 요구가 언제 처리될 것인지에 대한 추정치를 사용자가 알 수 있게 포함되어 있어야 한다.
- 204 No Content
- 서버가 요구 메시지의 내용을 처리하였으나 송신측으로 돌려보내줄 아무런 정보가 없을 때 사용한다. 만약 클라이언트가 사용자 에이전트라면 해당 요구를 만들어낸 문서 페이지의 내용이 바뀌어서는 안 된다. 이 응답은 특히 사용자 에이전트의 현재 문서 모습을 바꾸지 않고 어떤 실행 프로그램이나 다른 동작들에 대한 입력을 넣을 수 있도록 한다. 이러한 204 응답은 엔터티 헤더의 형태로 새로운 metainformation을 포함할 수 있고, 이것은 사용자 에이전트의 현재 문서 모습에 적용되어야 한다.
9.3 Redirection 3xx
이 클래스의 상태코드는 해당 요구를 수행하기 위해 사용자 에이전트에 의해 수행되어야 할 추가적인 동작이 있음을 나타낸다. 뒤이은 요구 메시지의 method가 GET 또는 HEAD인 경우에, 이 동작은 사용자와 아무런 상호동작 없이 사용자 에이전트에 의해 곧바로 수행될 수도 있다. 사용자 에이전트는 5번 이상 요구 메시지를 자동적으로 방향전환 (redirect) 시켜서는 안 되며, 이런 방향전환이 자주 무한루프를 돌게 만들 수 있기 때문이다.
- 300 Multiple Choices
- 이 응답코드는 HTTP/1.0 응용 프로그램에 의해 직접적으로 사용되지 않고, 3xx 클래스 응답을 해석하기 위한 기본 상태코드로서 활용한다. 요청받은 자원이 하나 또는 그 이상의 장소에서 가능할 수도 있다. 요구 메시지가 HEAD method가 아니라면 응답은 반드시 자원의 특성이나 위치 정보들을 담은 엔터티를 가져야 하고, 사용자나 사용자 에이전트는 이 정보로부터 가장 적절한 것을 선택할 수 있게 된다. 만약 서버가 적절한 선택을 하였다면 Location 필드에 URL을 포함하고 있어야 하고 사용자 에이전트는 자동 방향전환을 위해 이 필드를 사용할 수도 있다.
- 301 Moved Permanently
- 요청받은 자원에 대해 새로운 영구적 URL이 확정되고 이 URL을 이용하여 앞으로 자원을 활용하게 된다. 링크 작성 기능을 가진 클라이언트는 서버로부터 전달받은 이 링크를 Request-URI의 링크로서 재설정하여야 한다.
이 새로운 URL은 응답 메시지의 Location 필드로부터 전달된 것이어야 하는데, HEAD 요구의 경우가 아니라면 응답의 Entity-Body는 새로운 URL에 대한 하이퍼링크를 가진 짤막한 설명문을 갖고 있어야 한다.
만약 POST 요구에 대한 응답으로 301 상태코드가 수신되면 사용자 에이전트는 사용자로부터 확인을 받지 않은 상태에서 요구 메시지를 자동 방향전환 시켜서는 안 된다. 왜냐하면 이것이 요구 메시지를 발생시킨 상황 조건에 대한 변화를 줄 수 있기 때문이다.
- [주] 301 상태코드를 수신한 후에 POST 요구를 자동 방향전환시키면 현재의 어떤 사용자 에이전트는 GET 요구로 바꾸어버리는 오류상황을 만들기도 한다.
- 302 Moved Temporarily
- 요청받은 자원을 다른 URL로 임시적으로 두는 것을 말한다. 방향전환이 (redirection) 가끔 바뀌어질 수 있기 때문에 클라이언트는 앞으로의 요구를 위해 Request-URI를 계속 사용하여야 한다. URL은 응답 메시지의 Location 필드로부터 얻어진 것이어야 한다. HEAD 요구의 경우가 아니라면 응답의 Entity-Body는 새로운 URL에 대한 하이퍼링크를 가진 짤막한 설명문을 갖고 있어야 한다.
만약 POST 요구에 대한 응답으로 302 상태코드가 수신되면 사용자 에이전트는 사용자로부터 확인을 받지 않은 상태에서 요구 메시지를 자동 방향전환 시켜서는 안 된다. 왜냐하면 이것이 요구 메시지를 발생시킨 상황 조건에 대한 변화를 줄 수 있기 때문이다.
- [주] 302 상태코드를 수신한 후에 POST 요구를 자동 방향전환시키면 현재의 어떤 사용자 에이전트는 GET 요구로 바꾸어버리는 오류상황을 만들기도 한다.
- 304 Not Modified
- 만약 클라이언트가 조건부 GET 요구를 전달하고 이것이 허용되지만 If-Modified-Since 필드에 명시되어 있는 날짜와 시간 이후로 해당 자원이 수정되지 않았다면 서버는 이 상태코드로 응답하여야 하고 클라이언트에게 Entity-Body를 보내서는 안 된다. 응답 메시지에 포함되어 있는 헤더 필드는 캐시 관리자와 관련된 정보나 엔터티의 Last-Modified 날짜와 무관하게 변경될 수 있는 정보만 포함하고 있어야 한다. 이와 관련된 헤더 필드는 Date, Server, 및 Expires 등이다. 캐시는 304 응답에 들어있는 새로운 필드값을 반영하게끔 캐시되어 있는 엔터티를 적절히 처리하여야 (update) 한다.
9.4 Client Error 4xx
4xx 클래스의 상태코드는 클라이언트에 의해 생긴 오류 상황들에 대해 사용하는 것이다. 클라이언트가 서버에게 보내는 요구 메시지를 완전히 처리하지 못한 상태에서 4xx 응답을 받게 될 때, 클라이언트는 즉시 서버로 보내는 데이타 전송을 중단하여야 한다. HEAD 요구에 대해 응답할 때를 제외하고 서버는 일시적이든 영구적이든 이 오류 상황에 대한 설명문을 가진 엔터티를 포함시켜야 한다. 이러한 상태코드는 어떤 종류의 요구 method이든 적용된다.
- [주] 만약 클라이언트가 데이타를 보내고 있는 중이라면 TCP에 관한 서버 구현은 유의하여야 하는데, 클라이언트는 자신의 입력 연결을 해제하기에 앞서 서버가 보낸 응답 패킷을 수신했음을 인식할 수 있어야 한다. 클라이언트가 연결 해제 후에도 서버에게 데이타를 계속 보낸다면 서버는 클라이언트에게 해제 (reset) 패킷을 보내야 하고, 클라이언트는 HTTP 응용 프로그램이 입력 버퍼의 내용을 읽어서 또 다른 동작을 하기 전에 버퍼를 없애도록 하여야 한다.
- 400 Bad Request
- 보내진 요구가 메시지 형식에 맞지 않아서 서버가 이해할 수 없는 것으로 간주하여 보내는 상태코드이다. 클라이언트는 수정을 하지 않고 똑같은 요구를 반복해서 할 수는 없다.
- 401 Unauthorized
- 요구 메시지가 처리되기 위해 사용자 인증이 필요할 때가 있다. 이 경우에는 요청된 자원에 대해 적용되는 challenge를 포함시켜 서버가 WWW-Authenticate (10.16절 참조) 헤더 필드를 응답 메시지에 실어서 보낸다. 클라이언트는 적절한 Authorization (10.2절 참조) 헤더 필드와 함께 요구 메시지를 다시 보낸다. 요구 메시지가 이미 Authorization credentials를 갖고 있다면, 이때의 401 응답은 해당 credentials에 대해 인증이 거절되었다는 것을 의미한다. 만약 401 응답이 앞서의 응답과 같은 challenge를 갖고 있고, 사용자 에이전트가 적어도 한 번 인증 요청을 이미 시도했다면, 이때 사용자는 응답 메시지 속에 있는 엔터티의 내용을 받아야 한다. 왜냐하면 이 엔터티 속에 관련된 검사 정보가 들어있기 때문이다. HTTP 접근 제어는 11장에 설명되어 있다.
- 403 Forbidden
- 서버가 요구 메시지를 이해했지만 이의 수행은 거절할 수 있다. 인증에 의한 허가 사항이 반드시 이것까지 허용하는 것은 아닐 수 있으며, 이 경우에 요구가 계속 반복되어서는 안 된다. 만약 요구 메시지의 method가 HEAD가 아니고 요구가 처리되지 않는 이유를 서버가 밝히고자 한다면 엔터티 속에 이의 이유에 대한 정보를 실어서 보내도록 한다. 이 상태코드는 서버가 왜 요청을 거절했는지 이유를 밝히고 싶지 않을 때나 다른 응답은 적절하지 않을 때 통상 사용된다.
- 404 Not Found
- 서버가 Request-URI에 해당하는 아무 것도 발견하지 못했을 때 보내는 상태코드이다. 이것이 일시적인 것인지 영구적인 것인지에 대한 정보는 보내지 않는다. 만약 서버가 클라이언트에게 쓰일 수 있는 이런 정보조차 주고 싶지 않다면, 이 상태코드 대신에 403 (forbidden) 상태코드를 줄 수도 있다.
9.5 Server Error 5xx
5xx 클래스의 상태코드는 서버에게 일어난 오류상황이나 요구 사항을 처리할 수 없을 때 보내는 것이다. 만약 클라이언트가 요구를 완료하지 않았는데 5xx 상태코드인 응답을 받았다면 즉시 서버로 보내는 데이타 전송을 중단하여야 한다. HEAD 요구에 대해 응답할 때를 제외하고 서버는 일시적이든 영구적이든 이 오류상황에 대한 설명이 들어있는 엔터티를 함께 포함시켜야 한다. 이러한 응답코드는 어떤 종류의 요구 method에도 적용되며 이를 위한 헤더 필드는 따로 없다.
- 500 Internal Server Error
- 서버가 요청된 요구의 처리를 불가능하게 하는 예기치 못한 상황을 만났을 때 보내는 상태코드이다.
- 501 Not Implemented
- 서버가 요청된 요구에 대한 처리 기능을 지원할 수 없을 때이다. 이것은 서버가 이해할 수 없는 요구 method를 받았을 때나 이것을 어떤 자원에 대해서든 적용할 수 없을 때 가장 적절한 응답이 된다.
- 502 Bad Gateway
- 서버가 게이트웨이나 프락시로서 동작하고 있는 동안에 요구를 수행하도록 하기 위해 통과해가는 경로에 있어 다음 경로 서버 (upstream server) 로부터 부적절한 응답을 받은 경우에 사용되는 것이다.
- 503 Service Unavailable
- 서버가 일시적인 과부하나 서버 관리의 문제 때문에 지금 현재에 해당 요구를 처리할 수 없을 때 사용된다. 이것은 약간의 시간 지연 후에는 다시 처리할 수 있는 일시적 상황이란 의미를 가진다.
- [주] 503 상태코드의 존재는 서버가 과부하 상태일 때 반드시 이것을 사용해야 한다는 것을 의미하는 것은 아니다. 어떤 서버 프로그램은 아예 연결을 거절하기도 한다.
10. 헤더 필드 정의 (Header Field Definitions)
이 장에서는 HTTP/1.0 프로토콜의 헤더 필드들의 정의에 대한 표현 형식과 정의에 대한 내용을 다룬다. 여기서 송신측과 수신측은 클라이언트가 될 수도 있고 서버가 될 수도 있으며 누가 메시지를 보내고 받느냐에 따라 결정된다.
10.1 Allow
Request-URI에 의해 지정되는 대상체 지원하는 methods들을 나열하고 있다. 이것은 지정된 문서에 대해 적용할 method의 종류들을 수신측에게 알려주기 위해 사용된다. POST method를 사용하는 요구 메시지에는 Allow 필드가 허용되지 않는다. 그러므로 포함되어 있다면 무시하여야 한다.
다음과 같이 구성되어 있다.
이의 예를 아래와 같이 보일 수 있다.
이 필드는 클라이언트가 사용할 수 있는 method를 제한하는 데 사용된다. 그러므로 이러한 지정 사항을 준수하여야 하고, 원서버에 의해 허용되는 method의 종류가 결정된다. Allow 헤더 필드는 어떤 method가 서버에 구현되어 있는가를 나타내는 것은 아니다.
프락시는 명시되어 있는 method를 이해할 수 없다 해도 Allow 헤더 필드를 고쳐서는 안 된다. 이것은 사용자 에이전트가 원서버와의 통신에 있어 다른 수단을 사용할 수도 있기 때문이다.
10.2 Authorization
브라우저가 서버에게 서비스 요청을 할 때 자신의 신분을 밝히고 인정받는 동작을 위해 사용되는 필드이다. 401 Unauthorized 응답을 수신한 이후라면 - 요구 메시지 속에 있는 Authorization 헤더 필드에 의해 이루어질 수 있다 - 반드시 이 필드를 사용할 필요는 없다. Authorization 필드는 요청받은 대상 자원에 대한 사용자 에이전트의 인증 정보를 포함하는 credentials 정보로 구성한다.
이것을 보다 상세히 나타내면 다음과 같다.
HTTP 접근 인증은 11장에 설명되어 있다. 하나의 요구가 인증되고 realm도 명시되면, 이 realm 내에서 같은 credentials은 다른 모든 요구에 대해 유효하여야 한다. Authorization 필드를 가진 요구에 대한 응답은 캐시되어서는 안 된다.
10.3 Content-Encoding
Entity 헤더의 Content-Encoding 필드는 전송 대상이 되는 개체에 지정된 media-type에 대한 추가적인 정보를 나타낸다. 수신측의 입장에서 볼 때는 Content-Type 헤더 필드에 지정되어 있는 데이타 형식으로 원상 복구하기 위해 어떤 디코딩 알고리즘을 사용해야 할지 결정하는 역할을 Content-Encoding 필드가 하게 된다. 이것은 주로 실제 데이타에 대한 변질 없이 데이타 압축을 가능하게 하기 위해 사용된다.
content-coding의 내용은 3.5절에서 살펴볼 수 있으며, 이의 예를 아래와 같이 보일 수 있다.
결국 Content-Encoding은 Request-URI에 의해 지정되는 대상 자원의 데이타 속성을 나타내는 것이다. 그러므로 대상 자원이 인코딩되어 저장되어 있을 때 수신측에서 이것을 활용하기에 앞서 디코딩할 수 있도록 한다.
10.4 Content-Length
Entity 헤더의 Content-Length 필드는 Entity-Body의 크기를 바이트 단위로 표시하여 수신측에게 알려주는 용도로써 쓰인다. 요구 메시지의 method가 GET이라면 전송하는 데이타의 실제 크기란 의미로서 전달되지만, HEAD라면 전송되어야 하는 데이타의 크기가 어느 정도인지 의미하는 것이다. 다음과 같이 구성되어 있다.
이의 예를 아래와 같이 보일 수 있다.
응용 프로그램에서는 이 필드의 값을 media-type에 무관하게 Entity-Body의 전송 크기로서 인식하여야 한다. Content-Length는 전송할 entity body를 가진 모든 HTTP 요구 메시지에 있어야 하며, 0 또는 이보다 큰 값이어야 한다. Content-Length 값이 없을 때 응답 메시지의 entity body의 길이를 결정하는 방법은 7.2.2절에 설명되어 있다.
- [주] 이 필드의 의미는 MIME에서 사용되는 의미와는 현격히 틀리다. MIME 에서는 "message/external-body" content-type에 사용되는 선택적 필드이지만, HTTP에서는 전송하기에 앞서 전송할 엔터티가 있을 때마다 사용하는 필드이다.
10.5 Content-Type
Entity 헤더의 Content-Type 필드는 수신측에게 전달하는 Entity-Body의 데이타 형식을 표시한다. 요구 메시지의 method가 GET이라면 전송하는 데이타의 형식이란 의미로서 전달되지만, HEAD라면 전송되어야 하는 데이타의 형식이 어떤 것인지 표시하는 의미이다. 다음과 같이 구성되어 있다.
media-type에 대한 설명은 3.6절에 있으며, 예를 들면 아래와 같이 보일 수 있다.
엔터티의 미디어 형식을 지정하기 위한 추가적인 사항은 7.2.1에 설명되어 있다.
10.6 Date
메시지가 만들어지는 날짜와 시간을 나타낼 때 쓰이며, RFC 822에서 정의하고 있는 orig-date와 같은 의미이다. 이 필드는 3.3절에서 설명하는 것과 같이 HTTP-date로 표현되며 아래와 같다.
이의 예는 다음과 같다.
메시지가 사용자 에이전트나 서버와의 직접 연결을 통해 수신되는 것이라면 수신측에서는 이 날짜를 현재 날짜로 간주할 수 있다. HTTP 프로토콜 동작의 첫 시발점의 입장에서 보면, 날짜라고 하는 정보는 캐시되어 있던 정보를 검증하기 위한 중요한 요소이므로 응답하는 서버에서는 항상 Date 헤더를 포함하고 있어야 한다.
클라이언트는 엔터티 내용을 포함하고 있는 메시지에 POST 요구의 경우에서와 같이 Date 헤더 필드를 실어서 보내야 한다. Date 헤더 필드 없이 수신된 메시지는, 메시지가 수신측에서 캐시되거나 Date를 요구하는 프로토콜을 통해 중계된다면 수신측에 의해 날짜가 할당되어야 한다.
이론적으로 날짜는 엔터티가 생성되기 직전의 순간을 반영해야 한다. 실제로는 메시지 생성 동안 언제든지 생성될 수 있다.
- [주] 이 문서 이전의 설명에서는 Entity-Body의 생성 날짜를 알리는 필드라고 정의하였다. 이 문서에서는 실제 사용을 염두에 두고서 의미를 바꾸었다.
10.7 Expires
Entity 헤더의 Expires 필드는 전달하는 데이타를 의미없는 대상으로 간주하는 시기를 표시한다. 다시 말해, 식품의 유효기간 표시와 같이 일정 기간 유효한 대상에 대해 그 시각을 지나서는 유효하지 않다고 지정할 때 사용하는 것이다. 만약 캐시되어 있는 데이타에 대해 이렇게 표시되어 있을 때라면 지정한 시각이 지나고 난 다음에는 캐시되어 있는 데이타를 지워도 되는 것이다.
응용 프로그램에서는 주어진 날짜 이후의 엔터티는 캐시하지 않아야 한다. 이러한 Expires 필드의 존재가 원래 해당 자원이 이 시각 이전 또는 이후에 변경 되었다거나 삭제되었다거나 하는 것을 의미하지는 않는다. 그러나 정보 제공자의 입장에 있어서는 이럴 수 있다는 것을 알고 있거나 의심해봐야 한다. 표시 형식은 3.3절에 있는 HTTP-date에 의해 정의된 것을 사용한다.
이의 예를 아래와 같이 보일 수 있다.
이렇게 지정된 날짜가 Date 헤더 필드에 의해 지정된 것보다 앞선 날짜거나 같은 날짜라면 수신측에서는 포함된 entity를 절대 캐시해서는 안 된다. 해당 자원이 사용자나 어떤 실행 프로그램에 의해 자주 변경될 가능성이 있는 것이라면 Expires 날짜도 그만큼 반영되어야 한다.
Expires 필드는 사용자 에이전트에게 화면표시를 다시 하게 하거나 (to refresh its display) 자원을 다시 획득하는 (to reload a resource) 등의 용도로 사용할 수 없다. 왜냐하면 이의 목적이 캐시 메카니즘에만 적용하는 것이고, 이런 메카니즘에서는 자원에 대한 새로운 요구가 들어올 때 해당 자원에 대한 유효기간 상태를 확인해봐야 하기 때문이다.
사용자 에이전트는 종종 history 메카니즘을 사용하기도 하는데, 이 경우에는 기본적으로 Expires 필드 기능을 사용하지 않는 것으로 한다.
- [주] 응용 프로그램은 Expires 헤더에 대한 여러가지 잘못된 구현 상황에서도 잘 동작할 수 있도록 만들어야 한다. 그래서 '0'나 부적절한 날짜 형식이 전달될 때는 그 즉시 유효기간 지났음의 (expires immediately) 의미로 간주하여야 한다.
10.8 From
요구 메시지의 From 헤더 필드에는 브라우저를 사용하여 요구 메시지를 보낸 사용자의 E-mail 주소가 들어간다. 이 주소는 RFC 822에 mailbox로 정의되어 있는 것과 같이 동작 시스템이 처리할 수 있는 (machine-usable) 것이어야 한다. 다음과 같이 구성된다.
이의 예를 아래와 같이 보일 수가 있다.
이러한 헤더 정보를 이용하여 이용자에 대한 정보를 축적할 수 있으며, 부적절하게 서비스 요청을 하는 사용자나 원하지 않는 사용자를 식별하는 수단으로 활용할 수도 있다. 그러나 이것을 사용자 접근 제어의 수단으로서 사용해서는 안 된다.
이 헤더 정보는 서비스 요청한 요구 메시지에 포함되어 있는 method에 대해 책임을 지는 사람이란 의미로서 해석된다. 특히, 로봇 에이전트를 사용하는 경우에 로봇을 수행시키는 사람의 연락 정보로서 반드시 들어가 있어야 한다. 이것을 통해 수신측에서 만약 문제가 발생했다면 경위 설명을 요구할 수 있을 것이다.
여기서 사용하는 E-mail 주소는 요구 메시지를 생성시키는 호스트 주소와는 별개로서 처리되어야 한다. 그래야만 프락시 서버를 통과하는 경우에도 최초 서비스 요청자의 주소가 그대로 전달될 수 있기 때문이고, 그리고 반드시 그리 되어야 한다.
- [주] 이 정보는 클라이언트에서 사용자의 동의 하에 전달되어야 한다. 이것은 사용자의 개인 취향 문제일 수도 있고, 사용자가 위치 하는 곳의 보안 정책에 의해서일 수도 있지만, 반드시 사용자가 요구 메시지를 보내기 전에 From 헤더 필드를 함께 보낼 것인지 보내지 않을 것인지 또는 수정할 것인지 결정할 수 있어야 한다.
10.9 If-Modified-Since
요구 메시지의 If-Modiied-Since 헤더 필드는 8.1의 설명에서와 같이 GET method와 함께 조건부 동작으로 활용된다. 즉, 브라우저가 요구하는 문서에 대해 서버는 이 필드에 지정되어 있는 시각 이후에 수정된 화일만 제공해준다. 지정 시각 이후에 변경되지 않아서 해당 문서를 전달하지 않을 경우에는 Entity-Body 없이 304 (not modified) 응답만 보낸다. 다음과 같이 구성되어 있다.
이의 예를 아래와 같이 보일 수가 있다.
조건부 GET method는 지정된 자원이 If-Modified-Since 헤더에 의해 주어진 날짜 이후에 수정된 경우에만 전달하도록 하는 것이다. 이것을 결정하는 알고리즘은 다음의 경우들을 포함한다.
- 만약 조건부 GET 요구가 200 (ok)가 아닌 다른 어느 상태를 유발하거나 전달된 If-Modified-Since 날짜가 부적절한 것이라면 응답은 일반적인 GET의 기능과 똑같이 처리되어야 한다. 서버의 현재 시각 및 날짜보다 늦는 경우에는 부적절한 것이다.
- 자원이 If-Modified-Since 날짜 이후로 수정되었다면 응답은 일반적인 GET에서의 경우와 똑같이 처리되어야 한다.
- 자원이 If-Modified-Since 날짜 이후로 수정되지 않았다면 서버는 304 (not modified) 응답을 돌려준다.
- [주] 여기에서 사용하는 '날짜'라는 용어는 3.3절의 의미대로 쓰이고 있기 때문에 단순한 일자만 의미하는 것이 아니라 3.3절에 설명되어 있는 것처럼 그 시점의 시각, 요일 등의 사항도 포함하는 의미로 쓰이고 있다.
이러한 기능의 목적은 짧은 데이타 교환의 방법을 통해 효과적으로 캐시 정보를 갱신하기 위함이다.
10.10 Last-Modified
Entity 헤더 필드에 들어가는 Last-Modified 필드는 송신측에서 이 문서의 마지막 작업 일자와 시간을 알려주는 용도로 쓰인다. 이의 정확한 의미는 수신측이 이 문서를 어떻게 처리해야 하는가를 알려주는 것이다. 만약 수신측에서 수신하는 문서의 Last-Modified 날짜가 수신측에 똑같이 저장되어 있는 복사본 문서의 날짜 이후 것이라면 수신측은 앞서 저장된 문서를 무효로서 인식하여 삭제하든지 대치하든지 구현상의 문제로서 적절히 처리한다. 다음과 같이 구성되어 있다.
이의 예를 아래와 같이 보일 수 있다.
이 헤더 필드의 정확한 뜻은 송신측의 구현과 원래 대상 자원의 특성에 따라 좌우된다. 화일의 경우에는 화일 시스템에서의 최종 수정 시각이 될 것이고, 동적으로 변화되는 부분을 가진 엔터티라면 해당 부분 요소들에 대해 최종 수정된 시각들의 집합에 대한 가장 최신 시각을 의미한다. 또한 데이타베이스 게이트웨이의 경우에서라면 레코드에 대한 가장 최근 갱신 시점을 의미하게 되고, 가상 객체 (virtual objects)에 대해서라면 내부 상태가 변화된 마지막 시점을 의미하는 것이다.
10.11 Location
응답 메시지의 Location 헤더 필드는 Request-URI에 의해 지정되어 있는 대상체의 정확한 위치를 표시한다. Redirection 3xx 상태 코드의 응답을 위해 location 정보는 대상체에 대한 자동 위치 변환을 (automatic redirection) 위해 서버가 결정하는 URL로서 표시되어야 한다. Request-URI에서는 상대적인 경로로 표시될 수 있었으나, 여기서는 절대 경로만 표시되어야 한다.
이의 예를 아래와 같이 보일 수 있다.
즉, Location의 용도는, 어느 URI로 요구 메시지를 수신한 서버가 해석을 해보니 클라이언트가 원하는 자원의 URI가 다른 장소 및 다른 이름으로 Redirection되어 있을 때, 최종 대상이 되는 이 자원의 새로운 URI가 Location의 절대 경로 정보로서 전달하는 것이다.
10.12 Pragma
General Header의 Pragma 필드는 요구/응답의 연쇄 동작에 따라 어느 수신측에 적용되는 변수로서 구현에 관련된 것들을 포함하는 데 쓰인다. 모든 Pragma 변수는 프로토콜의 관점에서 선택적인 동작을 지정한다. 하지만 어떤 시스템은 변수들에 대한 동작의 일관성을 요구하기도 한다.
아래와 같은 형식으로 쓰인다.
만약 "no-cache" 변수가 요구 메시지에 존재한다면 응용 프로그램에서는 해당 자원이 캐시되어 있을지라도 원래 위치하고 있는 서버로 요구 메시지를 전달해야 한다. 이것은 클라이언트가 보내는 요구에 대해 신뢰할 수 있는 응답을 받고자 할 때 쓰일 수 있으며, 또한 클라이언트에게 데이타 오류와 같이 문제가 발생한 캐시 문서를 갱신할 수 있도록 할 때 쓰일 수 있다.
Pragma 변수는 프락시나 게이트웨이 프로그램에 대한 중요성과 상관없이 이 프로그램에 의해 그대로 전달되어야 한다. 왜냐하면 이 변수들은 연이은 요구/응답의 고리를 (request/response chain) 따라 모든 수신측에 적용될 수 있기 때문이다. 특정한 수신측 만을 위한 변수를 따로 지정할 수 없다.
10.13 Referer
요구 메시지의 Referer 헤더 필드는 서버를 위해 사용하는 것인데, 클라이언트가 요청한 Request-URI 정보를 얻게된 원래 문서의 주소를 나타낼 때 쓰인다. 즉, A라는 문서를 브라우저에서 보고 있을 때 이 문서에 포함된 링크를 이용하여 B 문서를 요청한다고 하면, B 문서를 지시하는 Request-URI는 A라고 하는 문서에서 알려진 것이므로 B 문서를 요청하는 요구 메시지에 들어가는 Referer는 A가 된다.
이를 통해 서버는 하나의 문서에 대해 링크되어 있는 이전 문서들의 back-links를 구성할 수 있게 되고, URL 정보가 잘못 기재된 문서들을 추적할 수 있게도 된다. 만약 사용자가 직접 입력한 URI의 경우처럼 Referer가 없는 경우라면 절대 Referer를 전달해서는 안 된다.
이의 예를 아래와 같이 보일 수가 있다.
만약 부분적인 URI가 주어진다면, 이것은 Request-URI를 기준으로 하는 상대적 경로로서 해석된다.
- [주] 이러한 Referer 정보가 나타내는 링크 정보를 앞서의 From 정보처럼 개인 취향이나 보안 문제 때문에 서버에게 보내지 않고자 할 수도 있다. 그러므로 브라우저에서는 Referer 정보나 From 정보를 보낼 것인지 보내지 않을 것인지 결정할 수 있는 수단을 제공하여야 한다.
10.14 Server
응답 메시지의 Server 헤더 필드는 요구 메시지를 처리하기 위해 서버가 사용하는 프로그램에 대한 정보를 담고 있다. 이 필드는 제품에 관한 여러 가지 사항을 담을 수도 있으며 서버에 대한 정보를 알리는 데에 사용된다. 이렇게 여러 가지 사항이 올 수 있으므로 제일 중요한 요소부터 먼저 나열하도록 한다. 다음과 같이 구성되어 있다.
이의 예를 아래와 같이 보일 수 있다.
만약 이러한 응답 메시지가 프락시 서버를 거치게 된다면 프락시 서버는 자신에 대한 정보를 이 내용에 추가해서 보내서는 안 된다.
- [주] 그런데 이런 정보를 통해 어느 소프트웨어를 사용하고 있는지 알 수 있고 이를 통해 이미 알려진 보안 취약점을 활용하여 해킹을 할 수 있으므로 서버 구현자들은 이 정보를 보낼 것인지 안 보낼 것인지 선택할 수 있도록 구현하는 것이 좋다.
10.15 User-Agent
요구 메시지의 User-Agent 필드는 사용자가 요구 메시지를 생성시키는 브라우저에 대한 정보를 나타낸다. 이것은 통계적인 목적, 프로토콜 위배에 대한 추적, 특정 브라우저의 한계를 피하기 위한 적절한 응답의 목적으로 브라우저 종류 인식 등과 같은 목적으로 쓰일 수 있다. 이 정보가 반드시 필요한 것은 아닐지라도 사용자 에이전트는 요구 메시지에 이 정보를 포함하여야 한다. 이 필드에는 여러 개의 제품 명칭이 포함될 수 있으며 (3.7절 참조) 중요도에 따라 순서대로 나열하여야 하고 우선 순위가 높은 것을 앞에다 명시하도록 한다. 다음과 같이 구성되어 있다.
이의 예를 아래와 같이 보일 수 있다.
- [주] 현재 프락시 응용 프로그램들 가운데 어떤 것은 User-Agent 필드에 있는 목록에 자신의 제품 정보를 덧붙여서 보내기도 한다. 이것은 프로토콜 처리에 있어 애매하게 만들기 때문에 권장사항이 아니다.
10.16 WWW-Authenticate
사용자의 요구 메시지에 지정되어 있는 정보가 보안이 필요로 하는 것이라면 서버는 서비스를 제공해주기 위해 사용자의 인증을 요구할 것이다. 그러므로 서버는 WWW-Authenticate 필드를 포함시켜 응답 메시지를 브라우저에게 전달하도록 한다. 이러한 WWW-Authenticate 헤더 필드는 401 (unauthorized) 응답 메시지에는 반드시 포함되어야 하는 것이다. 다음과 같이 구성되어 있다.
HTTP 프로토콜에서의 사용자 인증 과정은 11장에서 설명되고 있다. 필드가 하나 이상의 challenge를 갖고 있거나 하나 이상의 WWW-Authenticate 헤더 필드가 있다면 사용자 에이전트는 WWW-Authenticate 필드 값을 파싱할 때 특별한 주의를 기울여야 한다. 왜냐하면 challenge의 내용이 ","로서 구분되는 일련의 인증 파라미터 리스트를 포함할 수 있기 때문이다.
11. 접근 인증 (Access Authentication)
HTTP/1.0 프로토콜에서는 서버가 클라이언트의 요구에 대해 검사하고 (challenge) 클라이언트가 인증 정보를 보내는 단순한 검사/응답 인증 메카니즘을 (challenge-response authentication mechanism) 사용하고 있다. HTTP에서는 인증 방식을 표시하기 위해 확장 가능하며 대소문자 가리지 않는 토큰을 사용하고 있고 이에 뒤이어 ","로 구분되는 attribute-value 쌍을 명시한다. attribute-value에는 인증에 있어 필요한 파라미터 정보가 들어간다.
다음과 같은 표현식을 활용하도록 한다.
401 (unauthorized) 응답 메시지는 사용자 에이전트의 인증 검사를 위해 원서버에 의해 사용되는 것이다. 이러한 응답은 요청된 자원에 대해 적용할 수 있는 적어도 하나의 challenge를 포함하는 WWW-Authenticate 헤더 필드를 갖고 있어야 한다. 다음과 같은 같은 표현식으로 나타낼 수 있다.
realm attribute는 대소문자를 가리지 않으며 challenge를 가지는 모든 인증 체계들에 대해 필요한 것이다. realm value는 대소문자를 구분하며 접근하고 있는 서버의 root URL과 결합하여 표시되어 보호할 대상 범위를 설정한다. 이러한 realm들은 서버에 있는 보호 자원들에 대해 여러 개의 보호 영역으로 나눌 수 있게 해주며, 각각은 독자적인 인증 체계와 인증 데이타베이스를 가질 수 있다. realm value는 문자열로서 원서버에 의해 할당되는 것이며, 인증 방식에 따라 추가적인 의미를 부여할 수 있다.
사용자 에이전트가 자기 자신을 서버로부터 인증받고자 한다면 - 401 응답을 수신한 이후라야 가능한 것은 아니다 - 요구 메시지 속에 Authorization 헤더 필드를 포함시켜서 보낸다. 이 필드는 요청된 자원의 보안 영역에 대해 사용자 에이전트의 인증 정보를 가진 credentials로서 구성된다.
사용자 에이전트가 credentials을 자동적으로 적용할 수 있는 범위는 보호 영역에 의해 결정된다. 앞서의 요구가 이미 인증되었다면, 인증 체계, 파라미터, 및 사용자 선호도에 의해 결정되는 일정 시간 동안 같은 credentials은 보호 범위 내의 모든 요구에 대해 재사용될 수 있다. 그렇지 않다면 하나의 보호 영역은 서버의 영역 밖으로 확장될 수 없다.
만약 서버가 요구 메시지와 함께 전달된 credentials을 접수하지 않고자 한다면 403 (forbidden) 응답을 보내어야 한다.
HTTP 프로토콜은 접근 인증에 대한 이러한 간단한 challenge-response 메카니즘에 대해 응용 프로그램의 제한을 두지 않는다. TCP 수송계층에서의 암호화나 메시지 캡슐화 방법과 추가적인 메카니즘이 사용될 수도 있으며, 이때 인증 정보를 포함하는 추가적인 헤더 필드를 정의할 수도 있다. 그러나 이러한 추가적인 메카니즘은 여기에서 정의하지 않도록 한다.
프락시 서버는 사용자 에이전트 인증을 위해 WWW-Authentication과 Authorization 헤더 필드를 원래 상태 그대로 중계해야 하고, Authorization을 포함하고 있는 요구 메시지에 대한 응답을 절대 캐시해서는 안 된다. HTTP/1.0에서는 클라이언트가 프락시와 인증하는 수단은 제공하지 않는다.
11.1 기본 인증 체계 (Basic Authentication Scheme)
"Basic" 인증 체계는 사용자 에이전트가 각 보안 영역에 대해 사용자 아이디와 비밀번호로 자신을 증명하는 모델에 기반하고 있다. 서버는 Request-URI에 지정된 영역에 대한 사용자 아이디와 비밀번호를 검사하여 통과될 때만 해당 요구에 대한 인증을 허가한다. 여기서 선택 가능한 인증 파라미터는 없다.
보안 영역 내의 어느 URI에 대해 인증되지 않은 요구를 수신하게 되면 서버는 다음과 같은 challenge를 응답하여야 한다.
여기서 "WallyWorld"란 Request-URI의 보안 영역을 명시하기 위해 서버가 부여하는 문자열이다.
인증을 받기 위해 클라이언트는 사용자 아이디와 비밀번호를 보내는데 두 개 사이의 구분은 가운데에 ":" 문자를 넣고 based64 인코딩을 하여 credentials에 넣어서 보낸다.
만약 사용자 에이전트가 사용자 아이디로서 "Aladdin" 비밀번호로서 "open sesame"를 넣어서 보내고자 한다면, 클라이언트의 인증 요청으로서 Authorization 헤더 필드를 사용하여 다음과 같이 될 것이다. (10.2절 참조)
이와 같은 기본 인증 방식은 비보호 인증 방식이며 클라이언트와 서버 사이의 TCP 연결이 공격으로부터 안전하다고 신뢰할만 하다는 전제 하에 활용하는 것이다. 그러므로 이 전제가 성립하지 않으면 이 방식은 공격으로부터 안전하다고 말할 수 없다. 현재의 개방형 네트워크에서는 이 전제가 성립한다고 할 수 없으므로 기본 인증 방식은 적당히 사용되어야 하며, 클라이언트는 서버와의 기본 인증을 위해 이 방식을 구현하여야 한다.
12. 보안 사항들
이 장은 응용 프로그램 개발자, 정보 제공자, 및 이용자에게 이 문서에 설명되어 있는 HTTP/1.0의 보안 한계점을 알리기 위한 것이다. 밝혀진 문제에 대한 명확한 해결책을 제시하는 것은 아니지만 위험을 줄이기 위한 방법적 제안들은 담고 있다.
12.1 클라이언트 인증
11.1절에 설명한 것처럼 기본 인증 방식은 사용자 인증에 대한 안전한 방법이 아니며 실제 네트워크를 통해 Entity-Body가 내용 그대로 전달되는 것을 피하지도 못 하는 방법이다. HTTP/1.0은 보안성을 높이기 위한 추가적인 인증 방식이나 암호화 메카니즘을 제공해주지 못 하고 있다.
12.2 안전한 Methods
클라이언트 소프트웨어 개발자들은 인터넷 상에서의 사용자가 이용하는 모든 동작들이 소프트웨어가 제공하는 것임을 인식하여야 하고, 사용자들에게 자신의 어떤 동작 실행이 자신에게나 또는 다른 사람들에게 예기치 않은 중요한 의미를 부여할 수도 있다는 것을 인식시켜야 한다.
특히, GET과 HEAD는 대상 자원의 획득이라는 의미 이외의 다른 어떤 것도 가지지 않기 때문에, "안전한" 것이라고 간주할 수 있다. 그러나 POST의 경우에는 안전하지 못한 어떤 동작을 실행시킬 가능성이 있음을 사용자에게 주지시켜야 한다.
서버가 GET에 대한 요구를 처리하는 과정에서 부수적인 다른 동작을 발생시키는지 사실상 잘 알 수 없다. (어떤 동적 자원은 이런 특성을 고려의 대상으로 삼고 있기도 하다.) 여기에 있어서의 차이점은 사용자가 이 부수 효과를 요구하지 않았다는 것이고 그러므로 이것을 추측할 수 없다는 점이다.
12.3 서버의 Log 정보의 남용
서버는 사용자의 요구로부터 사용자들의 독서 습관이나 관심 주제들에 대한 개인적 정보를 확보할 수 있는 위치에 있다. 이러한 정보는 분명히 개인적인 비밀 사항이며 어떤 나라에서는 이의 관리에 있어 법적인 제한을 받고 있다. 그러므로 데이타를 제공하기 위해 HTTP 프로토콜을 사용하는 사람들은 개개인들의 허락 없이 이런 자료들을 무단 배포해서는 안 된다는 것을 알아야 한다.
12.4 위험한 정보의 전달
일반적인 데이타 전송 프로토콜처럼 HTTP도 전송되는 데이타의 내용을 통제할 수가 없고, 특정 정보 부분의 중요도를 판단할 수 있는 수단도 없다. 그러므로 응용 프로그램은 정보 제공자에게 정보에 대한 통제 기능을 가능한한 많이 주어야 한다. 이를 위해 세 가지의 헤더 필드가 특별한 관심의 대상이 된다. 즉, Server, Referer, 및 From이다.
서버의 특정 소프트웨어 버전을 알리는 것은 해당 소트트웨어의 알려진 보안 취약점을 통해 서버 호스트가 직접 공격당하게 할 위험성을 제공하기 때문에, 구현 개발자들은 Server 헤더 필드를 관리자 설정이 가능하게끔 구현하여야 한다.
Referer 필드는 사용자의 읽기 습관에 대한 정보를 제공할 수 있고 꺼꾸로 역추적할 수 있는 열쇠를 제공할 수 있다. 이 필드는 매우 유용한 것임에도 불구하고 Referer에 포함되어 있는 정보로부터 추출될 수 있는 사용자 정보가 남용될 가능성이 있다. 개인 정보가 제거되었을 때조차 Referer 필드를 통해 개인적 비공개 문서에 대한 URI가 밝혀질 수 있다.
From으로부터 전달되는 정보는 사용자의 개인적 관심사나 사용자가 있는 곳의 보안 정책과 충돌할 수도 있으며, 이 때문에 사용자에게 제공 거부 또는 필드의 내용 수정의 선택 요소를 주지 않고 무조건 전달하게 해서는 안 된다. 사용자 선호도 또는 응용 프로그램 지정 사항 설정 환경에서 이 필드의 내용을 지정할 수 있게끔 사용자에게 제공하여야 한다.
이러한 정보가 반드시 필요한 것은 아님에도 불구하고, From과 Referer 정보를 보낼지 안 보낼 것인지 지정할 수 있는 간단한 토글 선택창을 제공하도록 권고한다.
12.5 화일과 경로 이름을 이용한 공격
HTTP 서버 구현은 서버 관리자가 제공하고자 하는 문서만 서비스될 수 있도록 하여야 한다. 만약 HTTP 서버가 HTTP URL을 화일 시스템 호출로 곧바로 동작시키면 서버는 HTTP 클라이언트에게 원하지 않는 화일을 제공하지 않도록 특별한 주의를 기울여야 한다.
예를 들어, Unix, MS Windows, 및 다른 운영체계는 현재 디렉토리 한 단계 앞을 지정하는 표시로 ".."를 사용하고 있는데, HTTP 서버에서는 Request-URI에 이런 형식의 지정을 허용하지 않아야 한다. 그렇게 하지 않으면 HTTP 서버를 통해 접근하도록 만든 범위 밖의 자원에 대한 원치 않는 접근을 가능하게 하기 때문이다.
비슷하게, 접근 제어 화일, 환경 설정 화일, 스크립트 실행 화일 등과 같이 서버 내부적으로 접근할 수 있게 한 파일들은 그 중요성 때문에 부당한 접근 시도로부터 방어를 하여야 한다. 그리고 서버 프로그램 구현상의 버그 때문에 보안 취약점이 발견되기도 한다.
13. 참고자료
부록 (Appendices)
여기의 부록은 HTTP/1.0 규격서에는 포함되지 않지만 정보 제공의 측면에서 기술되는 것이다.
A. 인터넷 미디어 형식 (Internet Media Type) message/http
이 문서는 HTTP/1.0 프로토콜에 대한 규격을 정의하는 동시에 인터넷 미디어 형식으로서 "message/http"에 대한 규격을 설명하는 역할도 한다. 다음의 사항이 IANA [13]에 등록되어 있다.
B. Tolerant Applications
이 문서가 HTTP/1.0 메시지 생성에 대한 규정 사항들을 다루고 있지만 모든 응용 프로그램들이 이 규정을 정확하게 구현하고 있는 것은 아니다. 그러므로 잘 동작하는 응용 프로그램을 만들기 위해서는 약간의 구현상 오류나 본래 의미에서 벗어난 구현 등과 같은 변화에 대해 잘 대처할 수 있도록 하여야 한다.
클라이언트는 Status-Line을 해석할 때 안정적이어야 (tolerant) 하며 서버는 Request-Line을 해석할 때 안정적이어야 한다. 특히 이들은 필드 사이에 하나의 SP만 허용될 때에라도 많은 수의 SP나 HT가 나오더라도 수용하고 대처할 수 있어야 한다.
HTTP-header 필드에 대한 줄끝 표시는 CRLF이다. 그러나 이런 헤더를 해석할 때 응용 프로그램에서는 줄끝 표시로서 앞서 나오는 CR을 무시하고 하나의 LF도 인식할 수 있어야 한다.
C. MIME과의 관계
HTTP/1.0은 인터넷 메일과 (RFC 822 [7]) MIME(Multipurpose Internet Mail Extension, [5])에 정의되어 있는 많은 구성 요소들을 활용하고 있는데, 엔터티들을 확장 가능한 메카니즘과 다양한 표현 형식으로 전송할 수 있도록 하기 위해서이다. 그러나 RFC 1521은 메일에 대한 설명을 하고 있으나 HTTP는 RFC 1521에 설명되어 있는 것과 약간 다른 기능을 갖고 있기도 하다. 이러한 차이점들은 이진모드 전송 연결 상에 있어 성능을 최적화하고, 새로운 미디어의 사용을 훨씬 더 자유롭게 하고, 날짜 비교를 더욱 쉽게 하며, HTTP 서버와 클라이언트의 활용성을 알리기 위한 목적으로 주의깊게 선택된 것들이다.
'96년 5월 현재, RFC 1521은 수정될 예정으로 있다. 이 수정 작업에 RFC 1521이 아니라 HTTP/1.0에서 발견된 활용적 잇점들이 반영될 수 있다.
이 부록은 HTTP와 RFC 1521의 차이점에 대해 몇 가지 부분으로 설명하고 있다. 엄정한 MIME 환경으로 통신을 하는 프락시와 게이트웨이는 이러한 차이점을 잘 알고 있어야 하고 필요하다면 적절한 변환도 할 수 있어야 한다. MIME 환경으로부터 HTTP로 통신하는 프락시와 게이트웨이는 어떤 변환이 필요할 수도 있으므로 이런 차이점들을 또한 알아야 할 필요가 있다.
C.1 Conversion to Canonical Form
RFC 1521은 인터넷 메일 엔터티가 전송되기 전에 RFC 1521 [5]의 부록 G에 설명한 바와 같이 표준적인 형태로 (canonical form)로 변환되어야 한다고 하고 있다. 지금 이 문서의 3.6.1절은 HTTP 상으로 전송할 때 "text" 미디어 형식에 대해 허용한 subtype의 형식들이 설명되어 있다.
RFC 1521은 "text"인 Content-Type 문서의 내용이 CRLF에 의해 줄바꾸기를 표시하도록 하고 있고, 줄바꾸기 부분 이외의 곳에서 CR이나 LF가 사용되지 않도록 하고 있다. 하지만 HTTP에서는 메시지가 전송될 때 내용 속에 든 줄바꾸기 표시에 대해 CRLF, CR, LF 각각의 존재를 인정하고 있다.
HTTP로부터 RFC 1521 환경으로 통신하는 프락시나 게이트웨이는 이 문서의 3.6.1절에 설명되어 있는 텍스트 미디어 내의 모든 줄바꾸기를 RFC 1521 표준 형태인 CRLF로 해석하여야 한다. 그러나 이것은 Content-Encoding의 존재와 HTTP가 CR과 LF를 의미하는 octet 13과 10을 사용하지 않는 어떤 문자집합을 허용한다는 사실에 의해 복잡하게 될 수 있다.
C.2 날짜 형식의 변환
HTTP/1.0은 날짜 비교 과정을 간단하게 하기 위해 3.3절과 같이 제한된 날짜 형식만 지원하도록 하고 있다. 다른 프로토콜로부터 중계하는 프락시나 게이트웨이는 메시지에 있는 어떤 형식의 Date 헤더라도 HTTP/1.0의 형식 가운데 하나로 따르도록 하고 필요하다면 날짜를 다시 만들도록 한다.
C.3 Content-Encoding 소개
RFC 1521에는 HTTP/1.0의 Content-Encoding 헤더 필드와 같은 의미를 가지는 기능이 없다. 이것은 미디어 형식에 대한 일종의 부연 설명의 요소로서 쓰이는 것이므로 HTTP로부터 MIME 지원 프로토콜로 통신하는 프락시나 게이트웨이는 Content-Type 헤더 필드의 지정 사항을 변경하거나 메시지를 포워딩 하기 전에 Entity-Body를 디코딩하여야 한다. (인터넷 메일에 대한 Content-Type을 실험적으로 구현한 으떤 응용 프로그램에서는 Content-Encoding과 똑같은 기능을 실행시키기 위해 ";conversions=<content-coding>"이란 media-type 파라미터를 사용하기도 한다. 그러나 이 파라미터는 RFC 1521에 정의되어 있는 것이 아니다.)
C.4 No Content-Transfer-Encoding
HTTP에서는 RFC 1521에 있는 Content-Transfer-Encoding (CTE) 필드를 사용하지 않고 있다. 그러므로 MIME 지원 프로토콜로부터 HTTP 프로토콜로의 통신을 제공하는 프락시나 게이트웨이는 HTTP 클라이언트에게 응답 메시지를 전달하기 전에 인식할 수 없는 CTE ("quoted-printable" or "base64") 인코딩을 디코딩시켜야 한다.
HTTP로부터 MIME 지원 프로토콜로 통신하는 프락시나 게이트웨이는 HTTP 프로토콜 상에서 안전한 전송을 위해 메시지가 정확한 형식과 인코딩으로 되어 있다는 것을 보장할 책임을 갖고 있다. 여기서 안전한 전송이란 사용하고 있는 프로토콜의 제한에 따라 정의된다. 이러한 프락시와 게이트웨이는 목적지에서 쓰이는 프로토콜 상에서 (MIME 지원 프로토콜) 안전한 전송의 가능성을 높이고자 한다면 전송하는 데이타에 대해 적절하게 Content-Transfer-Encoding 표시를 하여야 한다.
C.5 Multipart Body-Parts에서의 HTTP 헤더 필드
RFC 1521에서 multipart body-parts에 있는 대부분의 헤더 필드들은 필드 이름이 "Content-"로 시작하지 않으면 일반적으로 무시된다. HTTP/.10에서는 multipart body-parts가 해당 부분의 의미에 있어 중요한 HTTP 헤더 필드를 포함할 수도 있다.
D. 추가적인 기능들
여기서는 기존의 일부 HTTP 구현 프로그램에서 사용되고 있지만 대부분의 HTTP/1.0 응용 프로그램에서는 일관되고 정확하게 사용되고 있지 않은 프로토콜 요소들에 대해 기술하도록 한다. 구현자들은 이러한 것을 잘 숙지하도록 하여야 하지만, 다른 HTTP/1.0 응용 프로그램에서 이들 존재에 의존하거나 상호운용성에 의존하거나 할 수는 없다.
이러한 것들이 생기게 된 계기는 HTTP/1.0 프로토콜 규약이 확정되기 전까지 수시로 개정되던 드래프트들을 기준으로 일부 HTTP/1.0 응용 프로그램들이 개발되었기 때문이다. 예전의 드래프트에서 명시된 기능이 현재의 최종 확정 규약에는 포함되지 않은 경우들이 많은데, 이때 삭제된 부분들이 모든 HTTP/1.0 응용 프로그램에서 일관되게 동작하지 못하는 기능들이다.
D.1 추가적인 요구 Methods
D.1.1 PUT
PUT method는 같은 요구 메시지에 포함되어 있는 엔터티를 지정한 Request-URI에 저장하라는 것을 요구하는 것이다. 만약 Request-URI가 이미 존재하고 있는 자원을 가리키고 있다면 포함되어 있는 엔터티는 대상 자원에 대해 갱신된 최신의 것이라고 간주하도록 하여야 한다. 만약 기존의 자원을 가리키지 않고 있으며 이 URI가 요구하고 있는 사용자 에이전트에 의해 새로운 자원으로서 정의될 수 있다면, 원서버는 이 URI로 해당 자원을 생성시킬 수가 있다.
POST와 PUT 사이의 근본적인 차이는 Request-URI가 다른 의미를 가진다는 것이다. POST에서의 URI는 데이타 수신 프로세스, 다른 어떤 프로토콜과의 게이트웨이, 또는 주석문을 받아들이는 별개의 엔터티 등과 같은 어떤 자원 요소가 요구 메시지 내에 포함되어 있는 엔터티를 처리해야 할 데이타의 요소로서 지정한다는 것이다. 즉, URI는 요구 메시지에 포함되어 있는 엔터티를 활용할 데이타로서 처리하는 어떤 요소를 지정하고 있다.
반면에 PUT에 있어서의 URI는 요구 메시지에 포함되어 있는 엔터티를 지정하고 있으며, 사용자 에이전트는 어떤 URI가 쓰이고 있는지 알고 있으며 서버는 엔터티를 다른 자원요소로 적용하지 않아야 한다.
D.1.2 DELETE
DELETE method는 원서버에게 Request-URI에 지정되어 있는 자원을 삭제하도록 요청한다.
D.1.3 LINK
LINK method는 Request-URI가 지정하고 있는 기존의 자원과 기존의 다른 자원들 사이에 하나 또는 그 이상의 링크 관계를 생성시키는 역할을 한다.
D.1.4 UNLINK
UNLINK method는 Request-URI가 지정한 기존 자원으로부터 하나 또는 그 이상의 링크 관계를 해제시킬 때 사용한다.
D.2 추가적인 헤더 필드 정의
D.2.1 Accept
Accept 요구 헤더 필드는 요구에 대한 응답 메시지로서 허용할 수 있는 미디어 범위의 목록을 알려줄 때 사용한다. 그룹 지정으로서 "*" 글자가 쓰일 수 있으며, "*/*" 표시는 모든 종류의 미디어 형식을 허용한다는 뜻이고, "type/*" 표시는 해당 type에 대한 모든 종류의 subtype 형식을 허용한다는 뜻이다.
D.2.2 Accept-Charset
Accept-Charset 요구 헤더 필드는 기본 설정되는 US-ASCII와 ISO-8859-1 이외에 선호하는 문자집합의 목록을 지정할 때 사용한다. 이 필드는, 광범위한 문자집합이나 특수 목적의 문자집합을 지원하는 클라이언트가 해당 문자집합으로 문서를 표현할 수 있는 서버에게 자신의 처리능력을 알려줄 수 있도록 한다.
D.2.3 Accept-Encoding
Accept-Encoding 요구 헤더 필드는 Accept의 경우와 비슷하지만, 응답 메시지에 허용할 수 있는 content-coding 요소를 제한하는 것이다.
D.2.4 Accept-Language
Accept-Encoding 요구 헤더 필드는 Accept의 경우와 비슷하지만, 요구에 대한 응답으로서 선호하는 언어의 목록을 명시할 때 쓰인다.
D.2.5 Content-Language
Content-Language 엔터티 헤더 필드는 포함되어 있는 엔터티에 대해 적용되어 있는 언어를 표시한다. 이를 통해 어떤 사람들에게 이 엔터티가 유효할 것인지 나타낼 수 있다. 이 필드는 엔터티 내에 사용되는 모든 언어들을 전부 반영하지 못할 수도 있다.
D.2.6 Link
Link 엔터티 헤더 필드는 엔터티와 다른 어떤 자원 사이의 관계를 나타내는 수단으로 쓰인다. 하나의 엔터티는 여러 개의 링크값을 가질 수 있다. metainformation 레벨에서의 링크는 계층적인 구조와 이용 경로와 (navigation paths) 같이 관련성을 나타낼 수 있다.
D.2.7 MIME-Version
HTTP 메시지는 메시지를 구성하기 위해 사용한 MIME 프로토콜의 버전을 나타내기 위해 MIME-Version 일반 헤더 필드를 포함할 수도 있다. RFC 1521 [5]에서 정의하고 있는 것과 같이 MIME-Version 일반 헤더 필드의 사용은 메시지가 MIME 형식을 따르고 있음을 지정하는 것이어야 한다. 그러나 불행히도 기존의 오래전 HTTP/1.0 서버들의 경우에는 이것을 따르지 않고 있으므로 이 필드를 무시하여야 한다.
D.2.8 Retry-After
Retry-After 응답 헤더 필드는 서버의 서비스가 클라이언트에게 얼마 동안 제공되지 못 하는지 알려주기 위해 503 (service unavailable) 응답과 함께 쓰인다. 다른 관점에서 바라보자면 서버가 과부하와 같은 이유로 지금 현재 서비스를 제공할 수 없을 때 얼마 시간 후에 다시 요청하라는 의미로서 해석할 수 있는 것이다. 이 필드의 지정값은 HTTP-date 또는 응답을 보낸 시각 이후의 초 단위의 십진수로서 표시될 수 있다.
D.2.9 Title
Title 엔터티 헤더 필드는 엔터티의 제목을 표시하는 필드이다.
D.2.10 URI
URI 엔터티 헤더 필드는 Request-URI에 의해 명시되는 URI의 일부 또는 전부를 나타낼 수 있다. 요청된 자원이 이 URI를 통해 제공되는지는 보장할 수 없다.
마지막 수정: 1996. 11. 16. by 김 용 운
W3C HTTP/1.1: Header Filed Definitions 자료: http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.23
'Web > WEB기본' 카테고리의 다른 글
| [펌]HTML5와 HTML4의 차이점 (0) | 2008.06.25 |
|---|---|
| LightWindow 라이트박스의 업그레이드 (0) | 2008.06.10 |
| [펌]Yahoo User Interface Library(YUI) (0) | 2008.04.24 |
| javascript 이벤트 핸들러 (0) | 2008.04.22 |
| 링크에 대한 blur처리하기(css방식,script방식) (1) | 2008.04.01 |
| 외부문서 불러오기(AJAX) (0) | 2008.03.11 |
| 자스크립트로 마우스 위치 얻기(IE, FF) (0) | 2008.03.04 |
| [펌]웹해킹 시리즈 7) file upload 알고리즘 시의 주의할점 -4 (0) | 2008.01.23 |
(로그인하지 않으셔도 가능)